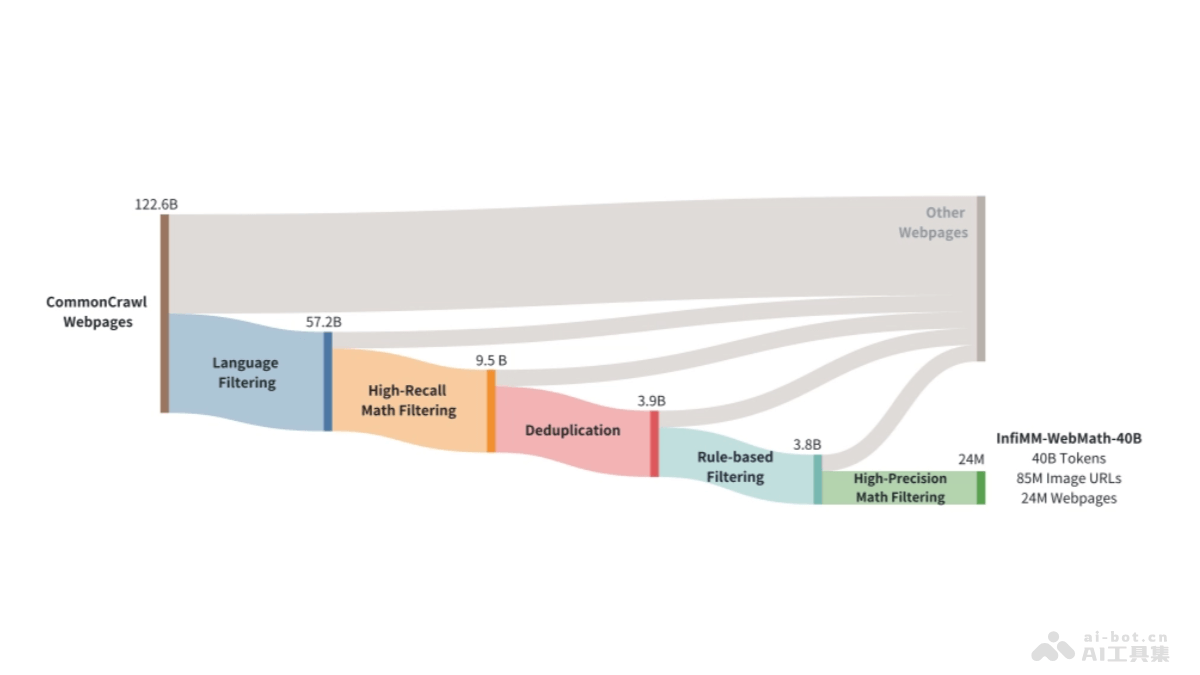
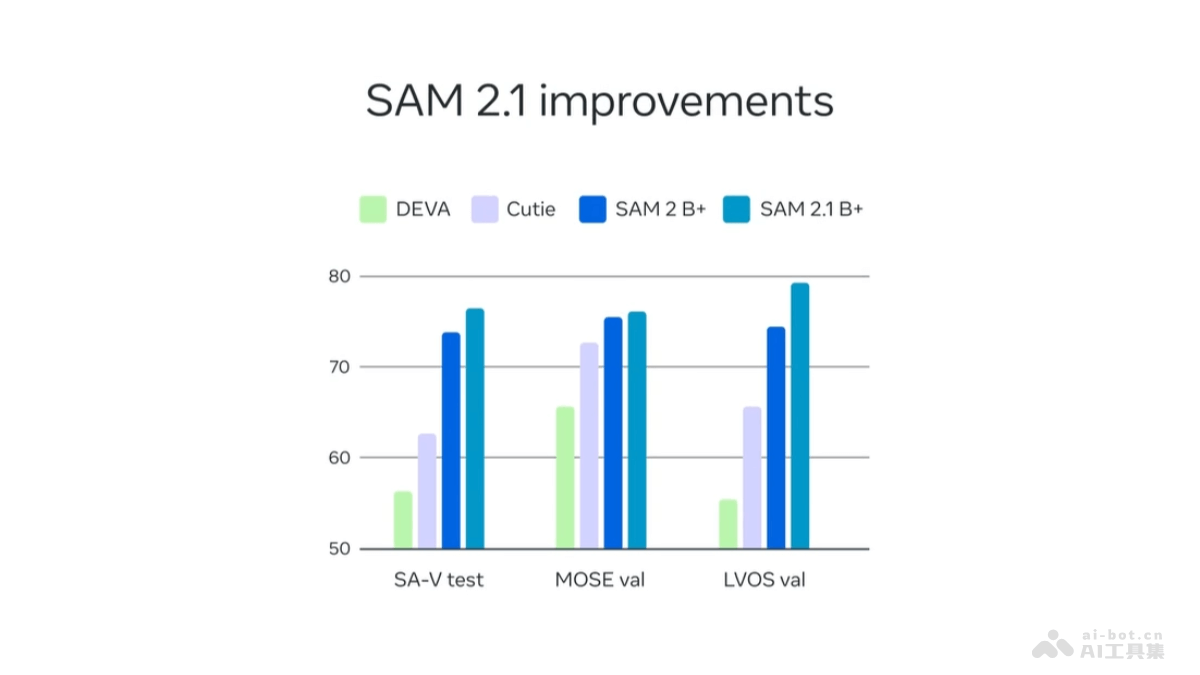
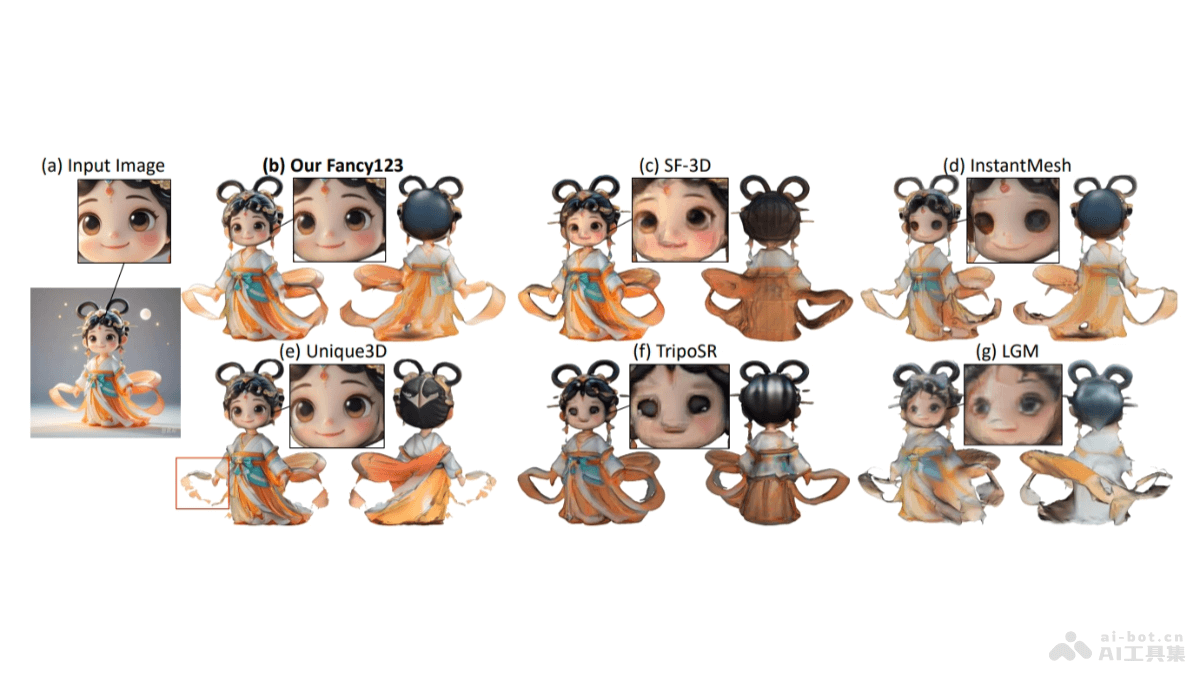
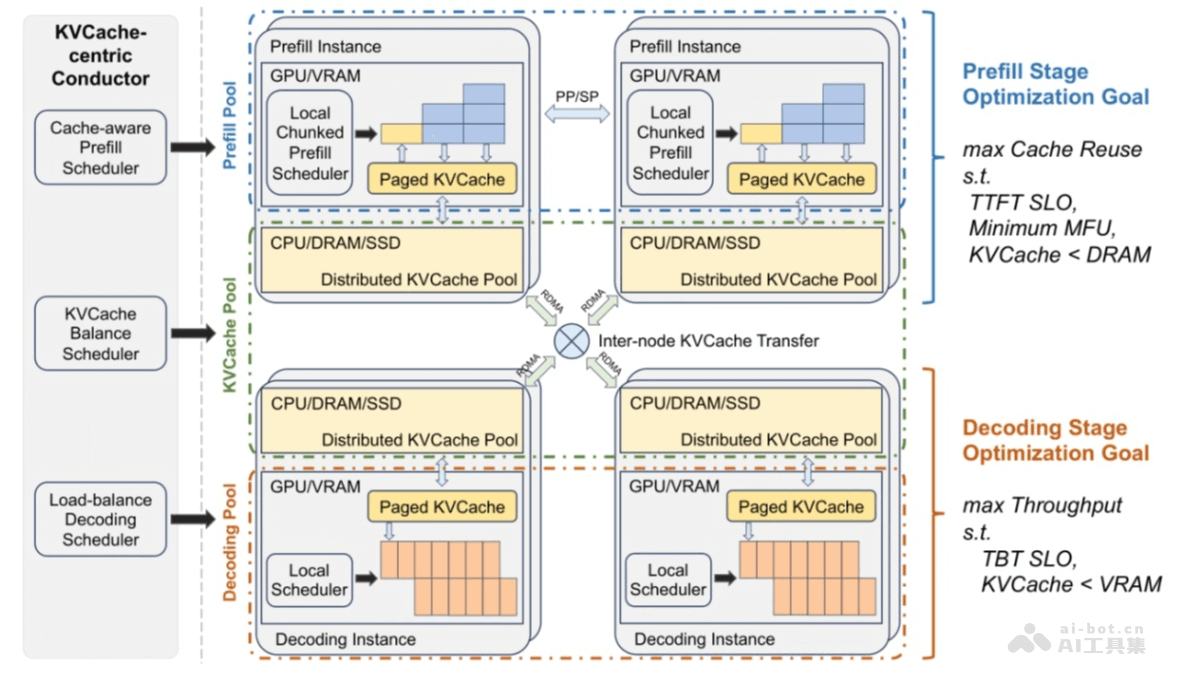
ShowUI是新加坡国立大学Show Lab和微软共同推出的视觉-语言-行动模型,能提升图形用户界面(GUI)助手的工作效率。模型基于UI引导的视觉令牌选择减少计算成本,用交错视觉-语言-行动流统一GUI任务中的多样化需求,并管理视觉-行动历史增强训练效率。ShowUI用小规模但高质量的指令跟随数据集,用256K数据实现75.1%的零样本截图定位准确率,训练速度提升1.4倍,展现出在GUI视觉代理领域的潜力。
 ShowUI的主要功能UI引导的视觉令牌选择:将屏幕截图构建为UI连接图,自适应地识别冗余关系,在自注意力模块中作为选择令牌的标准,减少计算成本。交错视觉-语言-行动流:灵活地统一GUI任务中的多样化需求,有效管理视觉-行动历史,提高训练效率。小规模高质量GUI指令跟随数据集:基于精心策划数据和采用重采样策略解决数据类型不平衡的问题,提高模型的准确性和效率。零样本截图定位:在没有额外训练的情况下,直接对屏幕截图进行理解和操作的能力。GUI自动化:自动化执行GUI任务,如点击、输入等,提高人机交互效率。ShowUI的技术原理UI引导的视觉令牌选择:将屏幕截图分割成规则的补丁(patches),每个补丁作为一个节点。识别具有相同RGB值的相邻补丁,构建UI连接图,将视觉冗余区域组合起来。在自注意力模块中,基于UI连接图选择性地处理视觉令牌,减少计算量。交错视觉-语言-行动流:结构化GUI动作,以JSON格式表示,统一不同设备上的动作。基于交替处理视觉、语言和行动数据,管理复杂的交互历史。在训练中,用多轮对话方式,提高数据利用效率。数据策划和重采样策略:精心策划和选择高质量的训练数据,而不是简单地聚合所有可用数据源。基于重采样策略,解决不同设备和任务类型之间的数据不平衡问题。高效处理高分辨率UI截图:针对高分辨率UI截图,优化模型以有效处理长令牌序列,减少计算成本。模型架构:基于Qwen2-VL-2B模型,整合视觉编码器和语言模型,处理视觉和文本数据。基于特定的数据食谱和训练策略,提高模型在GUI任务中的性能。ShowUI的项目地址GitHub仓库:https://github.com/showlab/ShowUIHuggingFace模型库:https://huggingface.co/datasets/showlab/ShowUI-desktop-8KarXiv技术论文:https://arxiv.org/pdf/2411.17465在线体验Demo:https://huggingface.co/spaces/showlab/ShowUIShowUI的应用场景网页自动化:自动执行网页上的点击、输入、滚动等操作,用在自动化测试、数据抓取或模拟用户行为。移动应用测试:在移动应用中自动化执行各种用户交互,如滑动、点击、填写表单等,进行应用功能测试。桌面软件自动化:自动化桌面软件中的重复性任务,如文件管理、数据输入、设置调整等。虚拟助手:作为虚拟助手的一部分,根据用户的自然语言指令执行特定的GUI操作。游戏自动化:在支持自动化脚本的游戏中,自动执行角色移动、物品拾取、战斗等操作。
ShowUI的主要功能UI引导的视觉令牌选择:将屏幕截图构建为UI连接图,自适应地识别冗余关系,在自注意力模块中作为选择令牌的标准,减少计算成本。交错视觉-语言-行动流:灵活地统一GUI任务中的多样化需求,有效管理视觉-行动历史,提高训练效率。小规模高质量GUI指令跟随数据集:基于精心策划数据和采用重采样策略解决数据类型不平衡的问题,提高模型的准确性和效率。零样本截图定位:在没有额外训练的情况下,直接对屏幕截图进行理解和操作的能力。GUI自动化:自动化执行GUI任务,如点击、输入等,提高人机交互效率。ShowUI的技术原理UI引导的视觉令牌选择:将屏幕截图分割成规则的补丁(patches),每个补丁作为一个节点。识别具有相同RGB值的相邻补丁,构建UI连接图,将视觉冗余区域组合起来。在自注意力模块中,基于UI连接图选择性地处理视觉令牌,减少计算量。交错视觉-语言-行动流:结构化GUI动作,以JSON格式表示,统一不同设备上的动作。基于交替处理视觉、语言和行动数据,管理复杂的交互历史。在训练中,用多轮对话方式,提高数据利用效率。数据策划和重采样策略:精心策划和选择高质量的训练数据,而不是简单地聚合所有可用数据源。基于重采样策略,解决不同设备和任务类型之间的数据不平衡问题。高效处理高分辨率UI截图:针对高分辨率UI截图,优化模型以有效处理长令牌序列,减少计算成本。模型架构:基于Qwen2-VL-2B模型,整合视觉编码器和语言模型,处理视觉和文本数据。基于特定的数据食谱和训练策略,提高模型在GUI任务中的性能。ShowUI的项目地址GitHub仓库:https://github.com/showlab/ShowUIHuggingFace模型库:https://huggingface.co/datasets/showlab/ShowUI-desktop-8KarXiv技术论文:https://arxiv.org/pdf/2411.17465在线体验Demo:https://huggingface.co/spaces/showlab/ShowUIShowUI的应用场景网页自动化:自动执行网页上的点击、输入、滚动等操作,用在自动化测试、数据抓取或模拟用户行为。移动应用测试:在移动应用中自动化执行各种用户交互,如滑动、点击、填写表单等,进行应用功能测试。桌面软件自动化:自动化桌面软件中的重复性任务,如文件管理、数据输入、设置调整等。虚拟助手:作为虚拟助手的一部分,根据用户的自然语言指令执行特定的GUI操作。游戏自动化:在支持自动化脚本的游戏中,自动执行角色移动、物品拾取、战斗等操作。