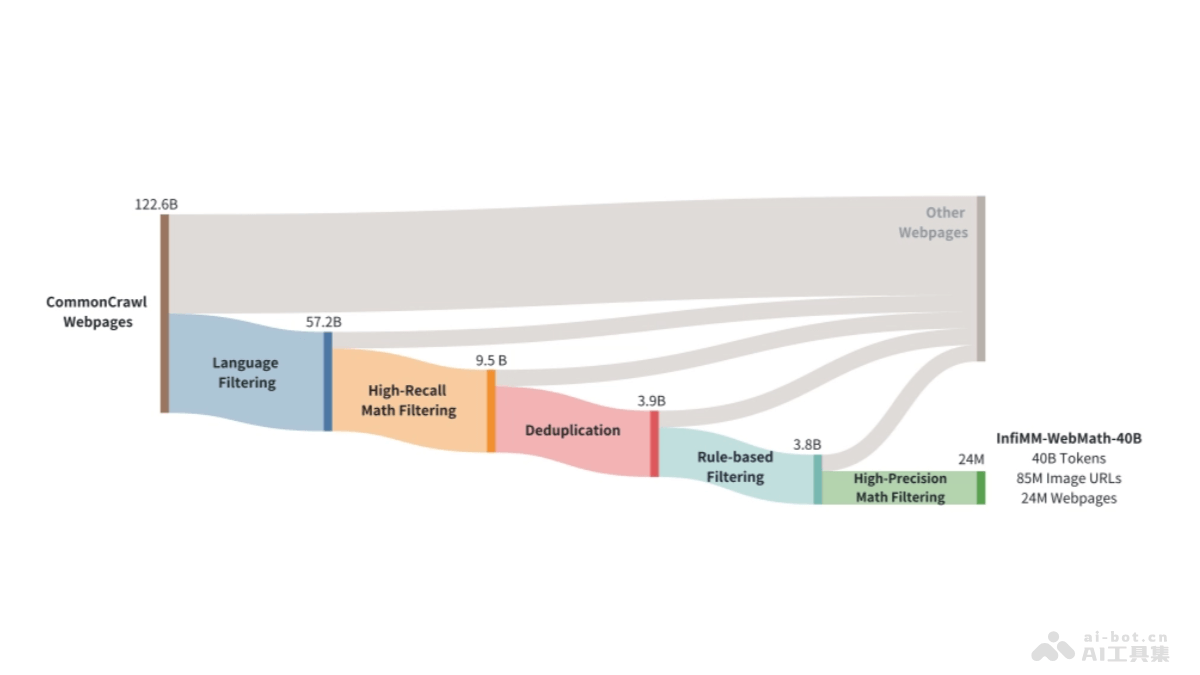
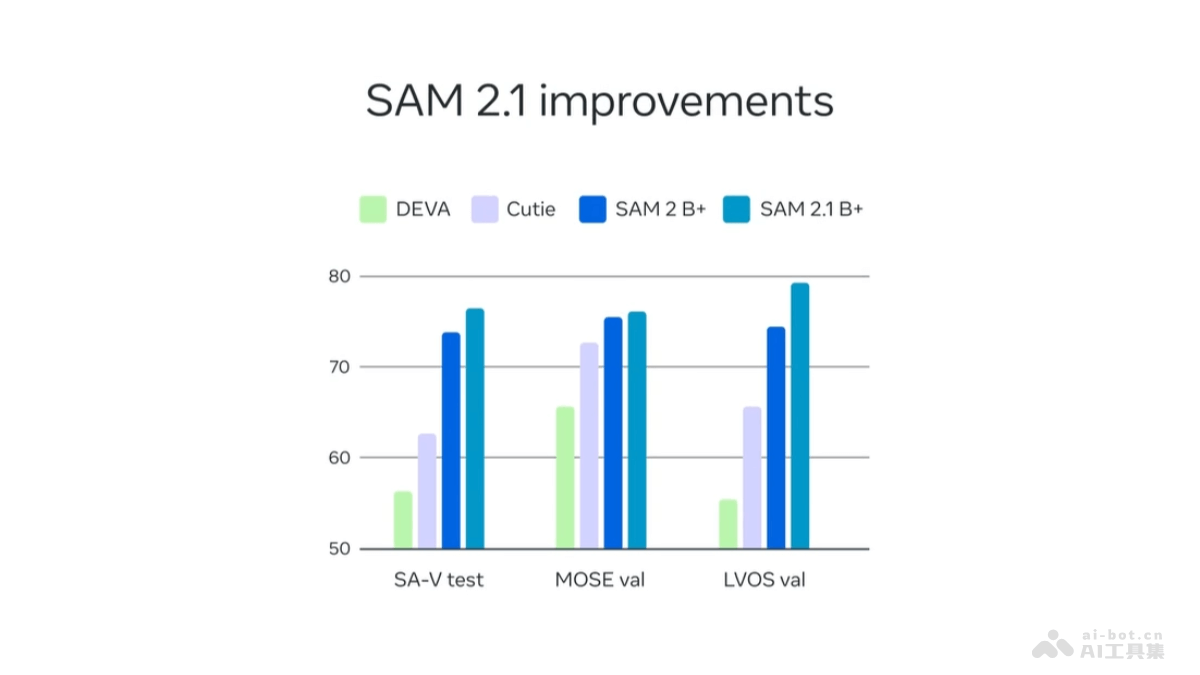
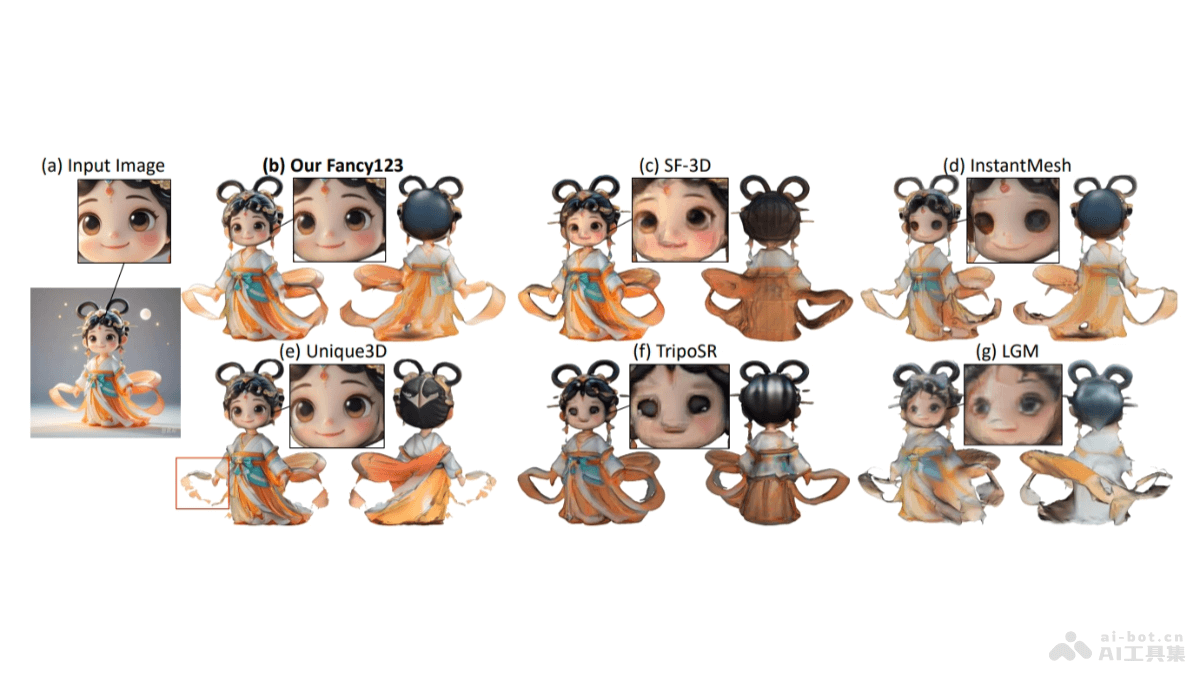
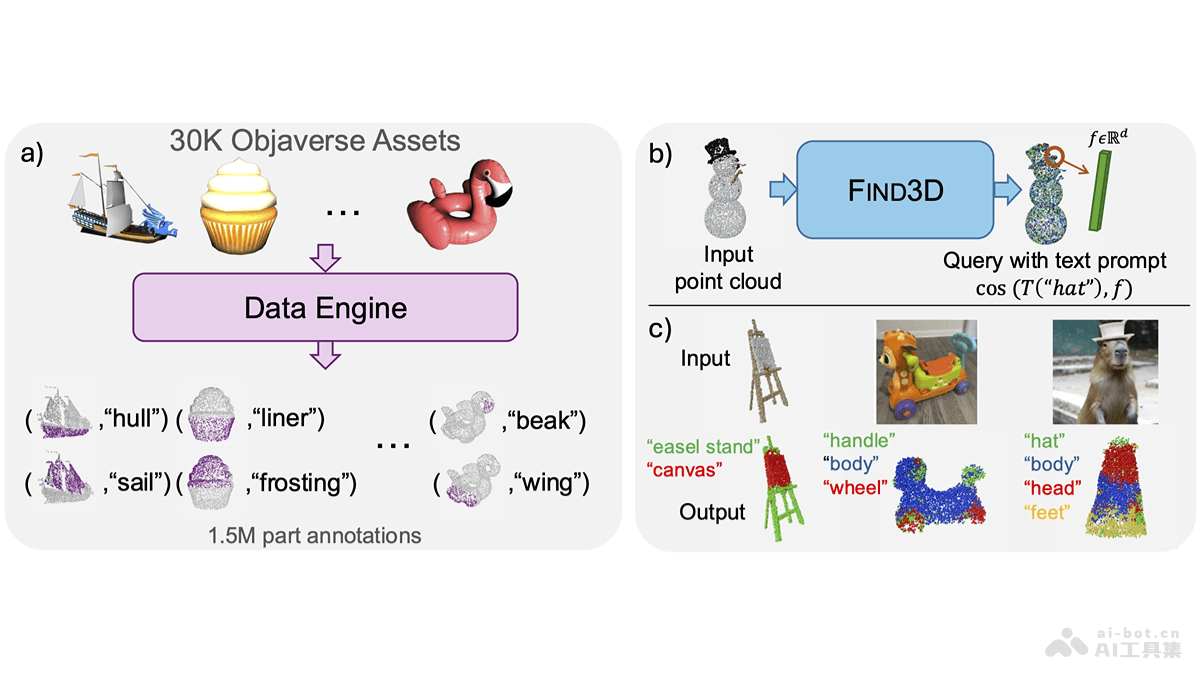
Mooncake是月之暗面Kimi联合清华大学等机构共同开源的大模型推理架构。采用以KVCache为中心的分布式架构,通过分离预填充和解码集群,充分利用GPU集群中未充分利用的CPU、DRAM和SSD资源,实现高效的KVCache缓存。Mooncake的核心优势在于能显著提升大模型推理的吞吐量,降低算力开销,在保持服务延迟相关的服务级别目标(SLO)的同时,处理高负载场景。架构在长上下文场景中表现出色,能显著提高吞吐量,同时支持基于预测的早期拒绝策略,优化过载情况下的资源分配。Mooncake项目在Github上开源,推动大模型技术的高效推理平台发展。
 Mooncake的主要功能高效的大模型推理:Mooncake通过其分布式架构,优化了大模型的推理过程,特别是在处理长上下文数据时,能显著提升推理吞吐量。KVCache中心化设计:以KVCache为中心,Mooncake实现了高效的数据缓存和重用,减少了对GPU资源的依赖,降低了算力开销。预填充与解码分离:架构将预填充(Prefill)和解码(Decode)阶段分开处理,资源可以针对不同阶段的计算特性进行优化。资源优化:通过分离式设计,Mooncake能更有效地利用CPU、DRAM和SSD资源,提高了资源利用率。负载均衡:Mooncake实现了基于缓存负载的均衡策略,通过自动热点迁移方案,提升了缓存命中率和系统负载的均衡。过载管理:面对高负载情况,Mooncake采用基于预测的早期拒绝策略,优化资源分配并减少无效计算。高性能传输:基于RDMA技术,Mooncake实现了跨节点的高速KVCache传输,降低了延迟。标准化接口:Mooncake为大模型时代打造新型高性能内存语义存储的标准接口,提供参考实现方案。成本降低:通过优化推理过程和资源利用,Mooncake有助于降低大模型推理的成本,AI技术更加经济高效。Mooncake的技术原理分布式架构:利用GPU集群中的CPU、DRAM和SSD资源,实现KVCache的分布式存储和传输,提高了缓存容量和传输带宽,降低了对单一GPU资源的依赖。全局调度器(Conductor):负责根据当前KVCache分布和工作负载情况调度请求,以及决定KVCache块的复制或交换,优化整体吞吐量和满足服务级别目标(SLO)。分块流水线并行(Chunked Pipeline Parallelism):对于长上下文请求,将输入标记分成多个块,并在不同的节点上并行处理,以减少延迟。Layer-wise预填充:异步加载和存储KVCache,通过重叠传输和计算,减少VRAM占用。缓存感知调度:Mooncake的调度算法考虑了KVCache的重用、预填充时间和实例负载的排队时间,以实现高效的请求调度。Mooncake的项目地址Github仓库:https://github.com/kvcache-ai/MooncakearXiv技术论文:https://arxiv.org/pdf/2407.00079Mooncake的应用场景自然语言处理(NLP):Mooncake可以用于支持各种NLP任务,如语言翻译、文本摘要、情感分析、问答系统和聊天机器人等。内容推荐系统:在推荐系统中,Mooncake可以用于处理用户行为数据和内容特征,提供个性化的推荐。搜索引擎:Mooncake可以用于改进搜索引擎的查询理解和文档排名,通过理解复杂的查询意图和文档内容,提供更准确的搜索结果。语音识别和生成:在语音识别领域,Mooncake可以用于提高语音到文本的转换准确性;在语音生成领域,可以生成更自然和流畅的语音输出。图像和视频分析:高效的推理能力也可以辅助图像和视频分析任务,如图像标注、视频内容理解等。智能客服和虚拟助手:Mooncake可以提供强大的后端支持,智能客服和虚拟助手能处理复杂的对话和任务。
Mooncake的主要功能高效的大模型推理:Mooncake通过其分布式架构,优化了大模型的推理过程,特别是在处理长上下文数据时,能显著提升推理吞吐量。KVCache中心化设计:以KVCache为中心,Mooncake实现了高效的数据缓存和重用,减少了对GPU资源的依赖,降低了算力开销。预填充与解码分离:架构将预填充(Prefill)和解码(Decode)阶段分开处理,资源可以针对不同阶段的计算特性进行优化。资源优化:通过分离式设计,Mooncake能更有效地利用CPU、DRAM和SSD资源,提高了资源利用率。负载均衡:Mooncake实现了基于缓存负载的均衡策略,通过自动热点迁移方案,提升了缓存命中率和系统负载的均衡。过载管理:面对高负载情况,Mooncake采用基于预测的早期拒绝策略,优化资源分配并减少无效计算。高性能传输:基于RDMA技术,Mooncake实现了跨节点的高速KVCache传输,降低了延迟。标准化接口:Mooncake为大模型时代打造新型高性能内存语义存储的标准接口,提供参考实现方案。成本降低:通过优化推理过程和资源利用,Mooncake有助于降低大模型推理的成本,AI技术更加经济高效。Mooncake的技术原理分布式架构:利用GPU集群中的CPU、DRAM和SSD资源,实现KVCache的分布式存储和传输,提高了缓存容量和传输带宽,降低了对单一GPU资源的依赖。全局调度器(Conductor):负责根据当前KVCache分布和工作负载情况调度请求,以及决定KVCache块的复制或交换,优化整体吞吐量和满足服务级别目标(SLO)。分块流水线并行(Chunked Pipeline Parallelism):对于长上下文请求,将输入标记分成多个块,并在不同的节点上并行处理,以减少延迟。Layer-wise预填充:异步加载和存储KVCache,通过重叠传输和计算,减少VRAM占用。缓存感知调度:Mooncake的调度算法考虑了KVCache的重用、预填充时间和实例负载的排队时间,以实现高效的请求调度。Mooncake的项目地址Github仓库:https://github.com/kvcache-ai/MooncakearXiv技术论文:https://arxiv.org/pdf/2407.00079Mooncake的应用场景自然语言处理(NLP):Mooncake可以用于支持各种NLP任务,如语言翻译、文本摘要、情感分析、问答系统和聊天机器人等。内容推荐系统:在推荐系统中,Mooncake可以用于处理用户行为数据和内容特征,提供个性化的推荐。搜索引擎:Mooncake可以用于改进搜索引擎的查询理解和文档排名,通过理解复杂的查询意图和文档内容,提供更准确的搜索结果。语音识别和生成:在语音识别领域,Mooncake可以用于提高语音到文本的转换准确性;在语音生成领域,可以生成更自然和流畅的语音输出。图像和视频分析:高效的推理能力也可以辅助图像和视频分析任务,如图像标注、视频内容理解等。智能客服和虚拟助手:Mooncake可以提供强大的后端支持,智能客服和虚拟助手能处理复杂的对话和任务。