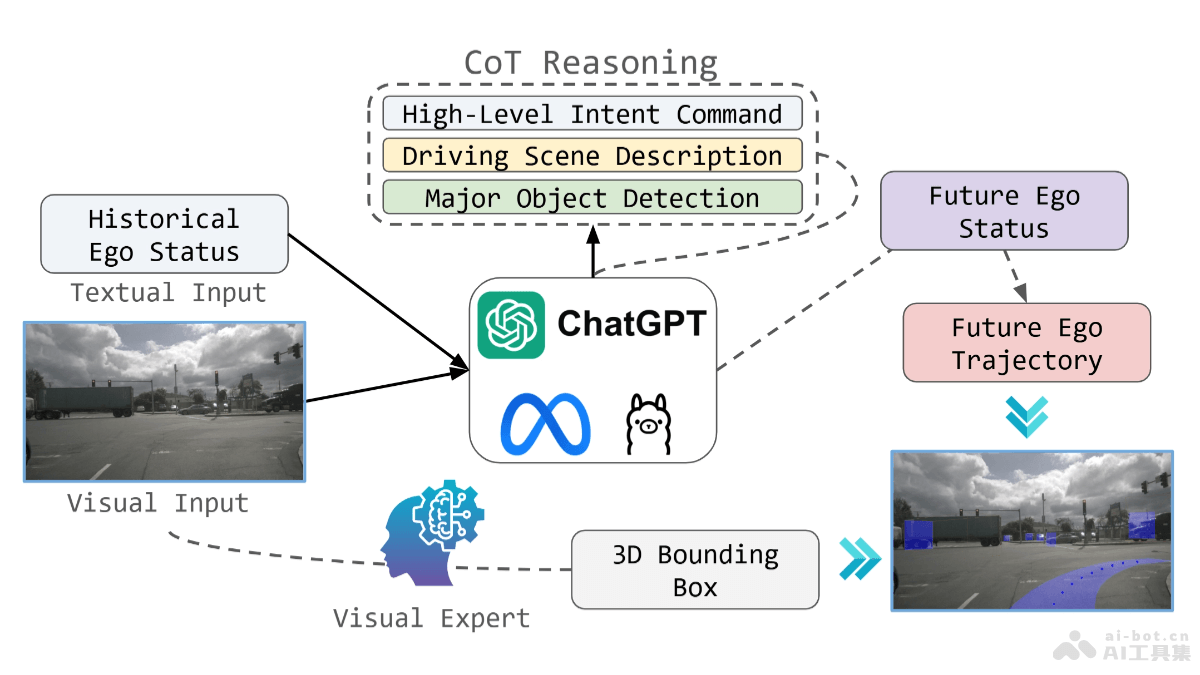
Skywork-Reward 是昆仑万维推出的一系列高性能奖励模型,包括 Skywork-Reward-Gemma-2-27B 和 Skywork-Reward-Llama-3.1-8B。主要用于指导和优化大语言模型的训练。模型通过分析和提供奖励信号,帮助模型理解和生成符合人类偏好的内容。在 RewardBench 评估基准上,Skywork-Reward 模型展现了卓越的性能,尤其在对话、安全性和推理任务中表现突出。其中,Skywork-Reward-Gemma-2-27B 模型在该排行榜上位列第一,证明了在AI领域的先进技术实力。
 Skywork-Reward的主要功能励信号提供:在强化学习中,为智能体提供奖励信号,帮助智能体学习在特定环境下做出最优决策。偏好评估:评估不同响应的优劣,指导大语言模型生成更符合人类偏好的内容。性能优化:通过精心策划的数据集训练,提升模型在对话、安全性和推理等任务上的表现。数据集筛选:使用特定策略从公开数据中筛选和优化数据集,提高模型的准确性和效率。多领域应用:处理包括数学、编程、安全性在内的多个领域的复杂场景和偏好对。Skywork-Reward的技术原理强化学习(Reinforcement Learning):一种机器学习方法,智能体通过与环境的交互来学习,目标是最大化累积奖励。Skywork-Reward 作为奖励模型,为智能体提供奖励信号。偏好学习(Preference Learning):Skywork-Reward 通过学习用户或人类的偏好来优化模型的输出。通过比较不同的响应对(例如,一个被选中的响应和一个被拒绝的响应),来训练模型识别和生成更受偏好的响应。数据集策划与筛选:Skywork-Reward 使用精心策划的数据集进行训练,数据集包含大量的偏好对。策划过程中,采用特定的策略来优化数据集,确保数据集的质量和多样性。模型架构:Skywork-Reward 基于现有的大型语言模型架构, Gemma-2-27B-it 和 Meta-Llama-3.1-8B-Instruct,提供了模型所需的计算能力和灵活性。微调(Fine-tuning):在预训练的大规模语言模型上,通过微调适应特定的任务或数据集。Skywork-Reward 在特定的偏好数据集上进行微调,提高其在奖励预测上的准确性。Skywork-Reward的项目地址GitHub仓库:https://github.com/SkyworkAI/Skywork-RewardHuggingFace模型库:27B模型地址:https://huggingface.co/Skywork/Skywork-Reward-Gemma-2-27B8B模型地址:https://huggingface.co/Skywork/Skywork-Reward-Llama-3.1-8BSkywork-Reward的应用场景对话系统:在聊天机器人和虚拟助手中,Skywork-Reward 用来优化对话质量,确保机器人生成的回答符合用户的偏好和期望。内容推荐:在推荐系统中,模型帮助评估不同推荐项的优劣,提供符合用户喜好的内容。自然语言处理(NLP):在各种 NLP 任务中,如文本摘要、机器翻译、情感分析等,Skywork-Reward 用来提升模型的性能,使输出更自然、准确。教育技术:在智能教育平台中,模型用来提供个性化的学习内容,根据学生的学习偏好和表现来调整教学策略。
Skywork-Reward的主要功能励信号提供:在强化学习中,为智能体提供奖励信号,帮助智能体学习在特定环境下做出最优决策。偏好评估:评估不同响应的优劣,指导大语言模型生成更符合人类偏好的内容。性能优化:通过精心策划的数据集训练,提升模型在对话、安全性和推理等任务上的表现。数据集筛选:使用特定策略从公开数据中筛选和优化数据集,提高模型的准确性和效率。多领域应用:处理包括数学、编程、安全性在内的多个领域的复杂场景和偏好对。Skywork-Reward的技术原理强化学习(Reinforcement Learning):一种机器学习方法,智能体通过与环境的交互来学习,目标是最大化累积奖励。Skywork-Reward 作为奖励模型,为智能体提供奖励信号。偏好学习(Preference Learning):Skywork-Reward 通过学习用户或人类的偏好来优化模型的输出。通过比较不同的响应对(例如,一个被选中的响应和一个被拒绝的响应),来训练模型识别和生成更受偏好的响应。数据集策划与筛选:Skywork-Reward 使用精心策划的数据集进行训练,数据集包含大量的偏好对。策划过程中,采用特定的策略来优化数据集,确保数据集的质量和多样性。模型架构:Skywork-Reward 基于现有的大型语言模型架构, Gemma-2-27B-it 和 Meta-Llama-3.1-8B-Instruct,提供了模型所需的计算能力和灵活性。微调(Fine-tuning):在预训练的大规模语言模型上,通过微调适应特定的任务或数据集。Skywork-Reward 在特定的偏好数据集上进行微调,提高其在奖励预测上的准确性。Skywork-Reward的项目地址GitHub仓库:https://github.com/SkyworkAI/Skywork-RewardHuggingFace模型库:27B模型地址:https://huggingface.co/Skywork/Skywork-Reward-Gemma-2-27B8B模型地址:https://huggingface.co/Skywork/Skywork-Reward-Llama-3.1-8BSkywork-Reward的应用场景对话系统:在聊天机器人和虚拟助手中,Skywork-Reward 用来优化对话质量,确保机器人生成的回答符合用户的偏好和期望。内容推荐:在推荐系统中,模型帮助评估不同推荐项的优劣,提供符合用户喜好的内容。自然语言处理(NLP):在各种 NLP 任务中,如文本摘要、机器翻译、情感分析等,Skywork-Reward 用来提升模型的性能,使输出更自然、准确。教育技术:在智能教育平台中,模型用来提供个性化的学习内容,根据学生的学习偏好和表现来调整教学策略。