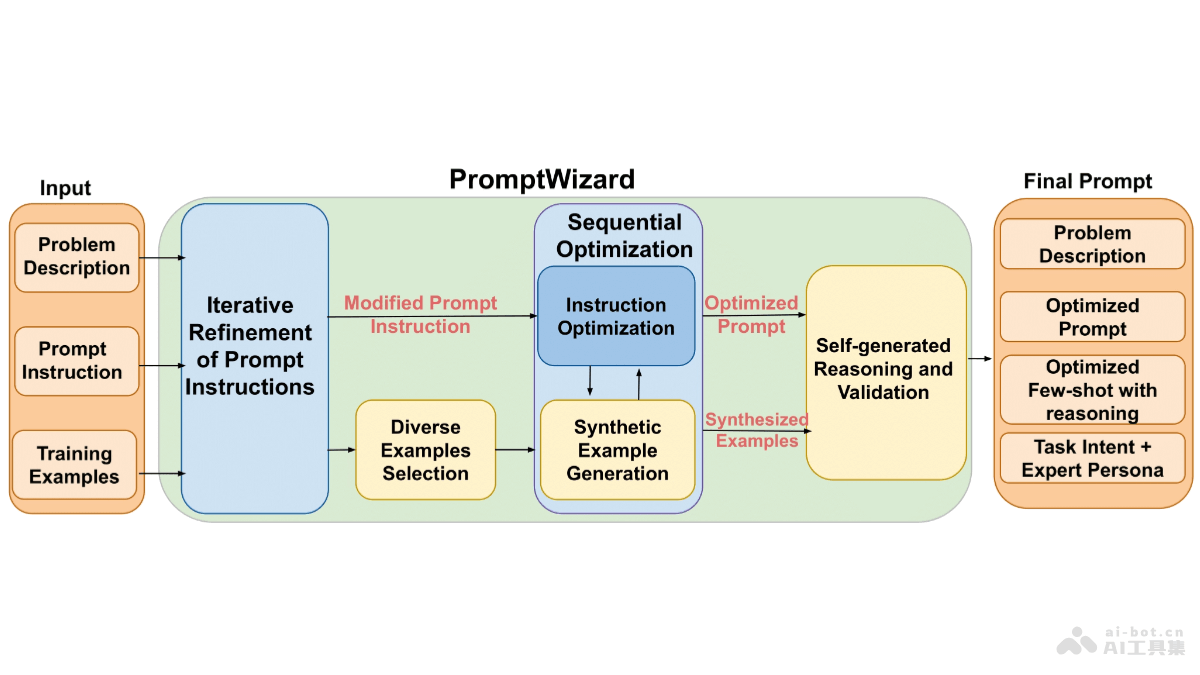
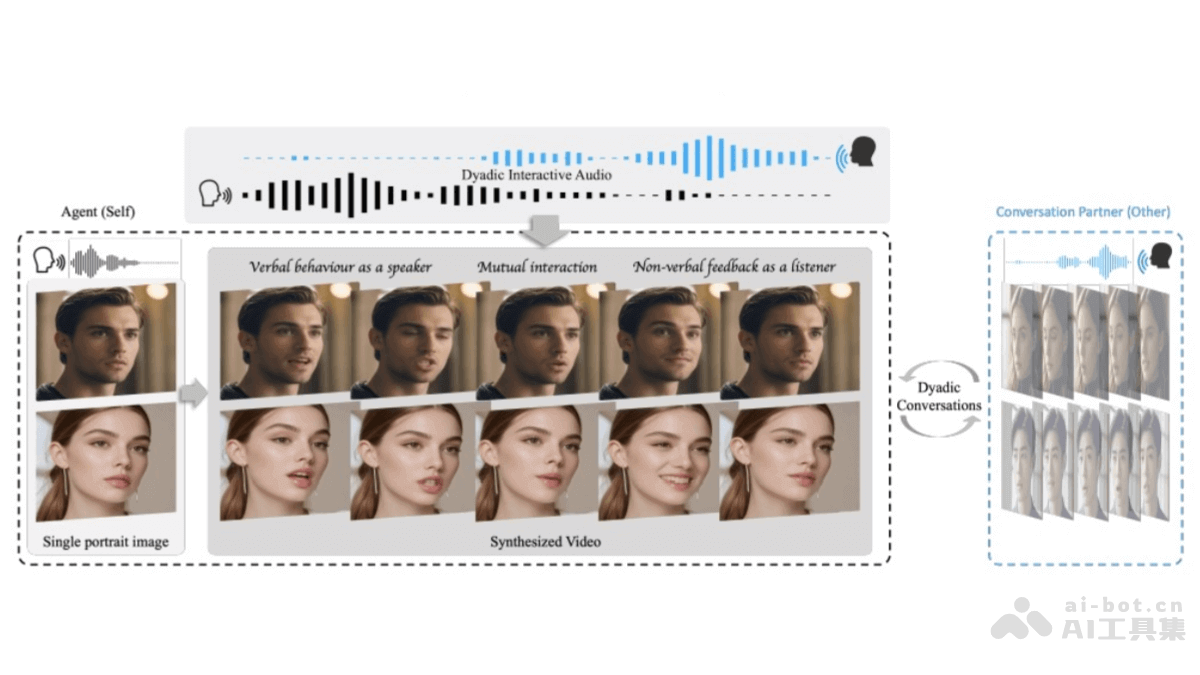
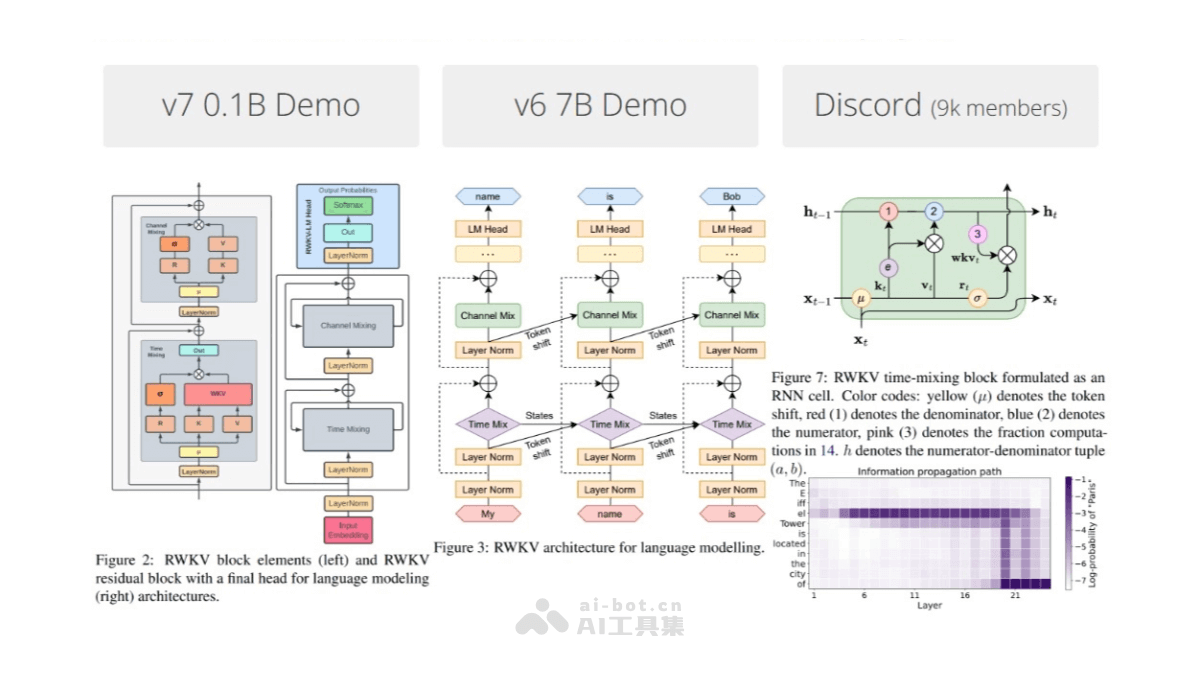
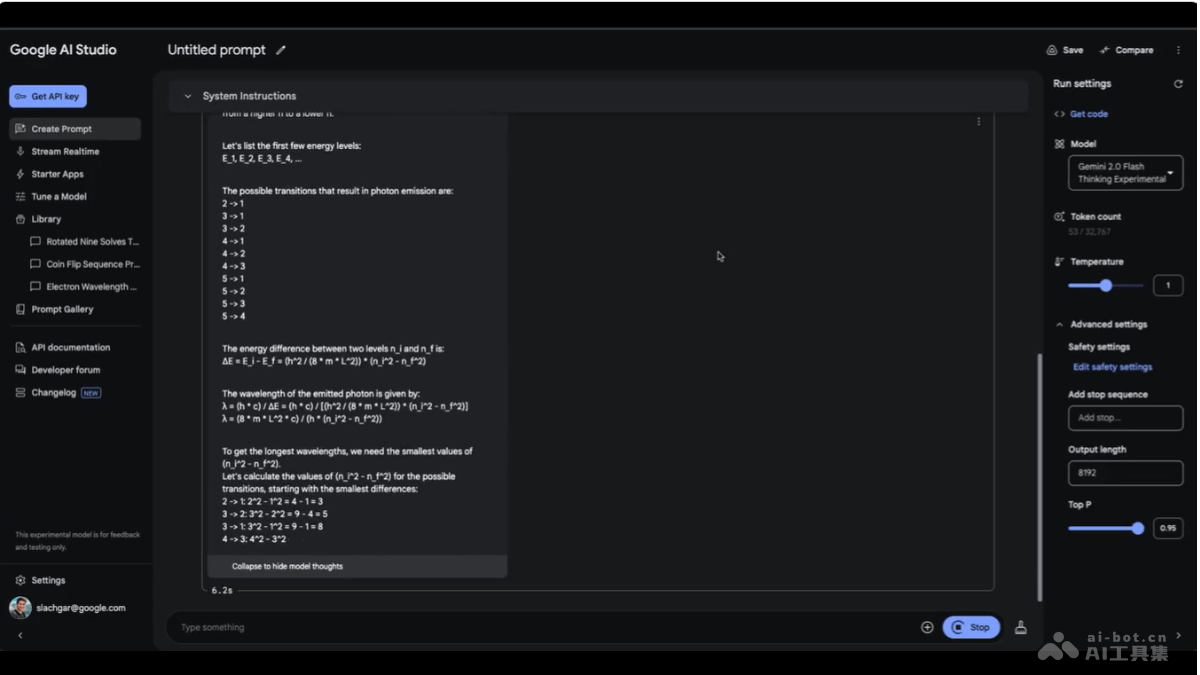
Surya是一款功能强大的开源OCR(光学字符识别)工具包,专门设计用在文档识别,支持超过90种语言的识别。Surya能准确识别出文档中的文本,分析文本的阅读顺序,检测文档中的布局元素,如表格、图片和标题,及识别和解析表格内容。Surya因高效的表格识别能力而闻名,性能优于许多现有的开源模型,如Table Transformer。Surya完全免费且用于商业用途,支持跨平台运行,包括Windows、Mac和Linux系统,适合处理敏感信息的离线环境。
 Surya的主要功能多语言OCR识别:Surya支持超过90种语言的光学字符识别,处理包括中文、日文、韩文、阿拉伯文等多种语言的文档。表格识别:Surya强化表格识别功能,能识别出文档中的行、列和单元格,甚至包括旋转和复杂布局的表格。复杂布局识别:Surya能识别文档中的复杂布局,例如标题、图片等,处理文档中的各种元素。文本检测与阅读顺序:Surya能进行文本的行级检测,确定文本的阅读顺序,确保输出的文本内容顺序正确。Surya的技术原理深度学习模型:Surya基于深度学习模型识别文档中的文本和布局元素。模型基于大量数据训练,识别和理解文档的结构和内容。语义分割:在文本检测方面,Surya基于深度学习的语义分割技术,将文档中的文本区域与非文本区域分开。对象检测:对于布局分析,Surya用对象检测技术识别文档中的不同元素,如表格、图片和标题等。序列模型:在阅读顺序检测中,Surya用序列模型分析文本行之间的相对位置和方向,确定正确的阅读顺序。优化的算法:Surya在算法层面进行优化,提高处理速度和准确性。Surya的项目地址GitHub仓库:https://github.com/VikParuchuri/suryaSurya的应用场景文档数字化:将纸质文档转换为电子格式,便于存储、检索和编辑。对于档案管理、图书馆数字化项目及个人文档整理都非常有用。数据提取:从表格、发票、报表等结构化文档中自动提取数据,用在数据分析、财务审计或数据库填充。多语言处理:支持90多种语言,Surya适合处理多语言环境下的文档,如跨国公司的文件处理、多语言书籍的数字化等。自动化办公:在办公室自动化中,Surya自动识别和处理邮件、信件、合同等文档,提高工作效率。学术研究:研究人员处理大量的科学文献、古籍或历史文档,快速提取文本内容,便于研究和分析。
Surya的主要功能多语言OCR识别:Surya支持超过90种语言的光学字符识别,处理包括中文、日文、韩文、阿拉伯文等多种语言的文档。表格识别:Surya强化表格识别功能,能识别出文档中的行、列和单元格,甚至包括旋转和复杂布局的表格。复杂布局识别:Surya能识别文档中的复杂布局,例如标题、图片等,处理文档中的各种元素。文本检测与阅读顺序:Surya能进行文本的行级检测,确定文本的阅读顺序,确保输出的文本内容顺序正确。Surya的技术原理深度学习模型:Surya基于深度学习模型识别文档中的文本和布局元素。模型基于大量数据训练,识别和理解文档的结构和内容。语义分割:在文本检测方面,Surya基于深度学习的语义分割技术,将文档中的文本区域与非文本区域分开。对象检测:对于布局分析,Surya用对象检测技术识别文档中的不同元素,如表格、图片和标题等。序列模型:在阅读顺序检测中,Surya用序列模型分析文本行之间的相对位置和方向,确定正确的阅读顺序。优化的算法:Surya在算法层面进行优化,提高处理速度和准确性。Surya的项目地址GitHub仓库:https://github.com/VikParuchuri/suryaSurya的应用场景文档数字化:将纸质文档转换为电子格式,便于存储、检索和编辑。对于档案管理、图书馆数字化项目及个人文档整理都非常有用。数据提取:从表格、发票、报表等结构化文档中自动提取数据,用在数据分析、财务审计或数据库填充。多语言处理:支持90多种语言,Surya适合处理多语言环境下的文档,如跨国公司的文件处理、多语言书籍的数字化等。自动化办公:在办公室自动化中,Surya自动识别和处理邮件、信件、合同等文档,提高工作效率。学术研究:研究人员处理大量的科学文献、古籍或历史文档,快速提取文本内容,便于研究和分析。