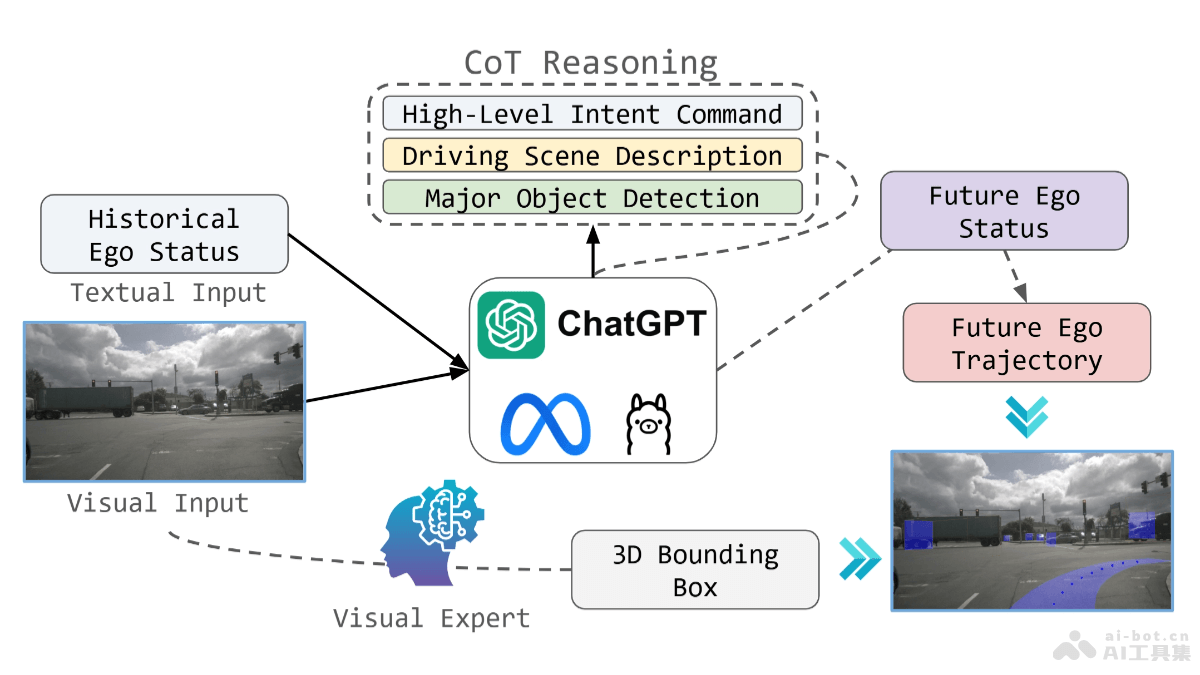
Ivy-VL是AI Safeguard联合卡内基梅隆大学和斯坦福大学推出的轻量级多模态AI模型,专为移动端和边缘设备设计。模型拥有3B参数量,相较于其他多模态大模型,显著降低计算资源需求,能在AI眼镜、智能手机等资源受限设备上高效运行。Ivy-VL在视觉问答、图像描述、复杂推理等多模态任务中展现卓越的性能,在OpenCompass评测中取得4B以下模型最佳成绩。
 Ivy-VL的主要功能视觉问答(Visual Q&A):理解和回答与图像内容相关的问题。图像描述(Image Description):模型能生成描述图像内容的文本。复杂推理(Complex Reasoning):处理涉及多步骤推理的视觉任务。多模态数据处理:在智能家居和物联网(IoT)设备中,处理和理解来自不同模态(如视觉和语言)的数据。增强现实(AR)体验:在智能穿戴设备中,支持实时视觉问答,增强AR体验。Ivy-VL的技术原理轻量化设计:Ivy-VL仅有3B参数,在资源受限的设备上更加高效。多模态融合技术:Ivy-VL结合先进的视觉编码器和强大的语言模型,实现不同模态之间的有效信息融合。视觉编码器:用Google的
Ivy-VL的主要功能视觉问答(Visual Q&A):理解和回答与图像内容相关的问题。图像描述(Image Description):模型能生成描述图像内容的文本。复杂推理(Complex Reasoning):处理涉及多步骤推理的视觉任务。多模态数据处理:在智能家居和物联网(IoT)设备中,处理和理解来自不同模态(如视觉和语言)的数据。增强现实(AR)体验:在智能穿戴设备中,支持实时视觉问答,增强AR体验。Ivy-VL的技术原理轻量化设计:Ivy-VL仅有3B参数,在资源受限的设备上更加高效。多模态融合技术:Ivy-VL结合先进的视觉编码器和强大的语言模型,实现不同模态之间的有效信息融合。视觉编码器:用Google的google/siglip-so400m-patch14-384视觉编码器处理和理解图像信息。语言模型:结合Qwen2.5-3B-Instruct语言模型理解和生成文本信息。优化的数据集训练:基于精心选择和优化的数据集进行训练,提高模型在多模态任务中的表现。Ivy-VL的项目地址项目官网:ai-safeguard.orgHuggingFace模型库:https://huggingface.co/AI-Safeguard/Ivy-VL在线体验Demo:https://huggingface.co/spaces/AI-Safeguard/Ivy-VLIvy-VL的应用场景智能穿戴设备:提供实时视觉问答功能,辅助用户在增强现实(AR)环境中获取信息。手机端智能助手:提供更智能的多模态交互能力,如图像识别和语音交互,提升用户体验。物联网(IoT)设备:在智能家居和IoT场景中实现高效的多模态数据处理,如用图像和语音控制家居设备。移动端教育与娱乐:在教育软件中增强图像理解与交互能力,推动移动学习和沉浸式娱乐体验。视觉问答系统:在博物馆、展览中心等场所,用户用拍照提问,系统提供相关信息。