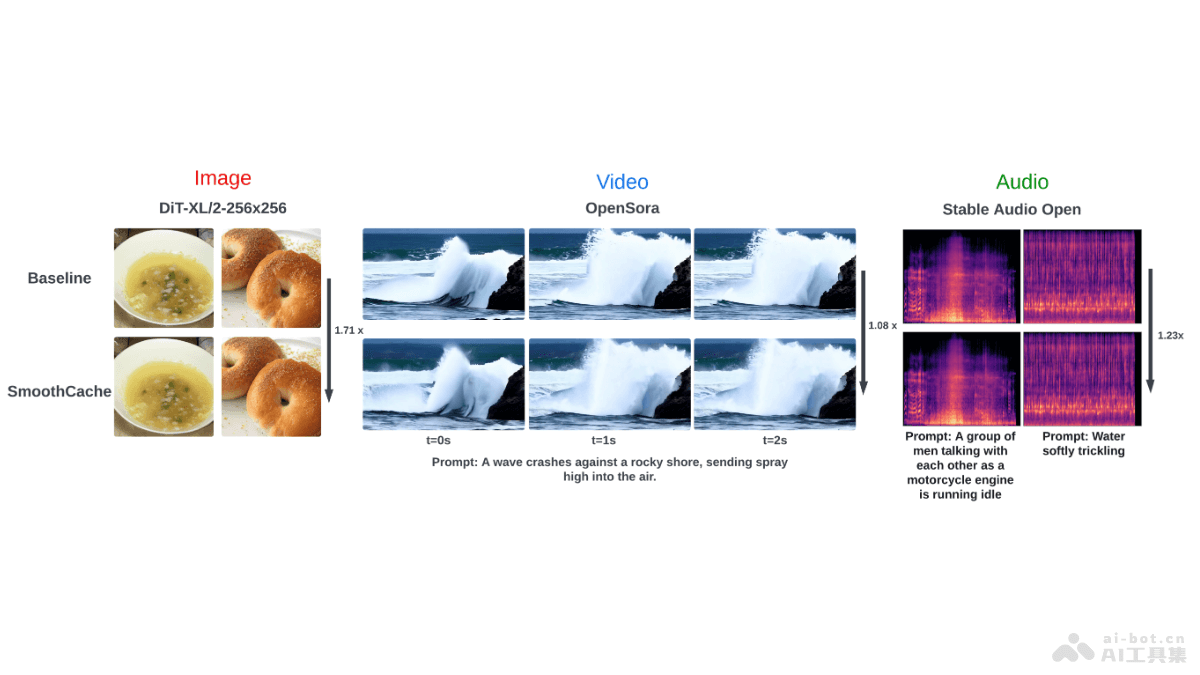
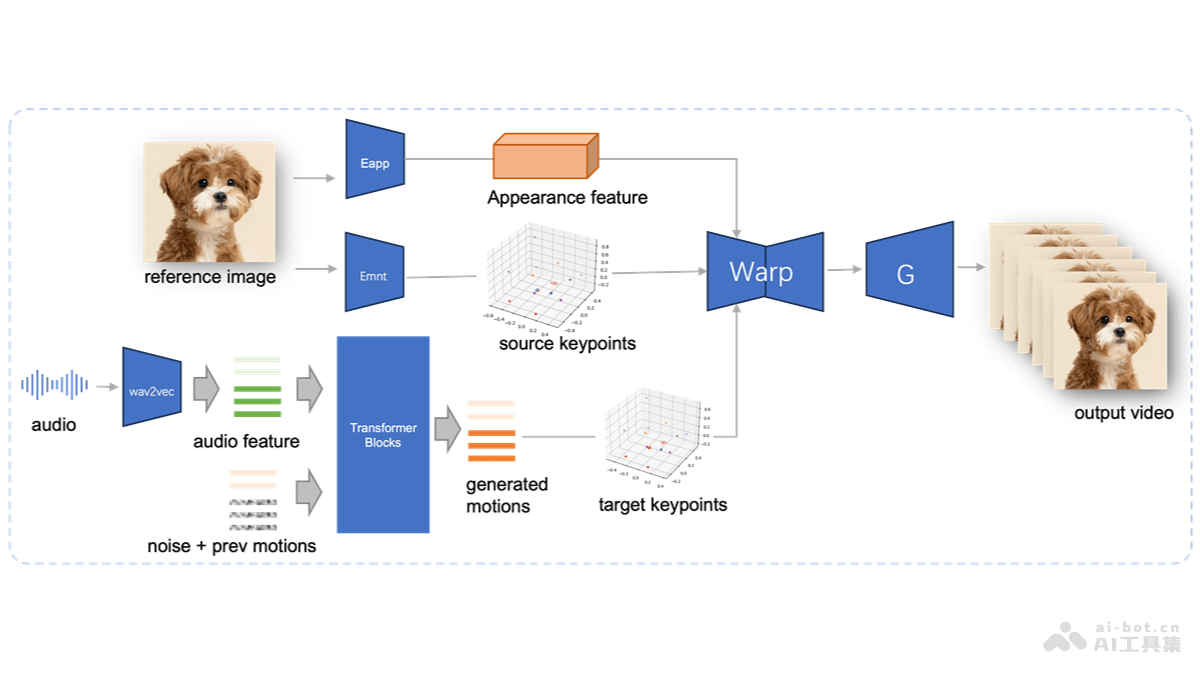
Gen2Act是由谷歌、卡内基梅隆大学和斯坦福大学共同推出的一种机器人操作策略,基于预测网络数据中的运动信息来生成人类视频,并将视频用在引导机器人执行新任务。策略基于大量可用的网络视频数据,避免直接生成机器人视频的复杂性。Gen2Act的核心在于零样本的人类视频生成,结合预训练的视频生成模型和少量的机器人交互数据训练策略。在真实世界的应用中,Gen2Act展现强大的泛化能力,能操作未见过的物体类型并执行新的动作,相较于其他方法,成功率显著提升。Gen2Act支持复杂任务的长时执行,例如连续完成“制作咖啡”等多步骤活动。这一方法减少了对大规模机器人数据采集的需求,用闭环策略动态调整提高操作的准确性。
 Gen2Act的主要功能零样本视频生成:Gen2Act能直接用预训练的视频生成模型,根据语言描述的任务和场景图像,生成人类执行任务的视频,无需针对特定任务进行微调。泛化到新任务:基于生成的人类视频引导,Gen2Act使机器人执行在训练数据中未出现过的新任务,包括操作未见过的物体类型和执行新的动作。闭环策略执行:结合生成的视频和机器人的实时观察,Gen2Act基于闭环策略动态调整机器人的动作,适应场景的变化准确执行任务。长时任务处理:Gen2Act能够完成单一任务,基于任务序列的链接,执行一系列复杂的长时任务,如“制作咖啡”,涉及到多个步骤的连续操作。减少数据需求:Gen2Act只需较少的机器人演示数据,大大降低数据收集的成本和工作量。Gen2Act的技术原理人类视频生成: 基于预训练的视频生成模型,根据语言描述的任务和场景的首帧图像,零样本生成人类执行任务的视频。视频到动作的翻译: 基于闭环策略,将生成的人类视频转化为机器人的动作。策略用视频的视觉特征和点轨迹预测隐式编码运动信息。视觉特征提取: 用ViT编码器和Transformer编码器从生成的视频和机器人的观察历史中提取特征。点轨迹预测: 基于轨迹预测Transformer预测视频中点的运动轨迹,辅助损失训练策略。行为克隆损失: 基于最小化预测动作和真实动作之间的误差优化策略,模仿人类视频中的行为。Gen2Act的项目地址项目官网:https://homangab.github.io/gen2act/arXiv技术论文:https://arxiv.org/pdf/2409.16283Gen2Act的应用场景家庭自动化:在家庭环境中,Gen2Act能操控家居设备,如开关微波炉、操作咖啡机、整理物品等,帮助实现家庭自动化。工业自动化:在制造业中,Gen2Act能执行复杂的装配任务,或者在需要灵活性和适应性的环境中替换或辅助人工操作。服务行业:在餐饮或零售服务中,Gen2Act指导机器人完成点单、上菜、整理货架等任务。医疗辅助:在医疗领域,Gen2Act帮助开发执行精细操作的机器人,如协助手术或递送医疗用品。灾难救援:在灾难救援现场,Gen2Act操控机器人在未知环境中进行搜索和救援任务。
Gen2Act的主要功能零样本视频生成:Gen2Act能直接用预训练的视频生成模型,根据语言描述的任务和场景图像,生成人类执行任务的视频,无需针对特定任务进行微调。泛化到新任务:基于生成的人类视频引导,Gen2Act使机器人执行在训练数据中未出现过的新任务,包括操作未见过的物体类型和执行新的动作。闭环策略执行:结合生成的视频和机器人的实时观察,Gen2Act基于闭环策略动态调整机器人的动作,适应场景的变化准确执行任务。长时任务处理:Gen2Act能够完成单一任务,基于任务序列的链接,执行一系列复杂的长时任务,如“制作咖啡”,涉及到多个步骤的连续操作。减少数据需求:Gen2Act只需较少的机器人演示数据,大大降低数据收集的成本和工作量。Gen2Act的技术原理人类视频生成: 基于预训练的视频生成模型,根据语言描述的任务和场景的首帧图像,零样本生成人类执行任务的视频。视频到动作的翻译: 基于闭环策略,将生成的人类视频转化为机器人的动作。策略用视频的视觉特征和点轨迹预测隐式编码运动信息。视觉特征提取: 用ViT编码器和Transformer编码器从生成的视频和机器人的观察历史中提取特征。点轨迹预测: 基于轨迹预测Transformer预测视频中点的运动轨迹,辅助损失训练策略。行为克隆损失: 基于最小化预测动作和真实动作之间的误差优化策略,模仿人类视频中的行为。Gen2Act的项目地址项目官网:https://homangab.github.io/gen2act/arXiv技术论文:https://arxiv.org/pdf/2409.16283Gen2Act的应用场景家庭自动化:在家庭环境中,Gen2Act能操控家居设备,如开关微波炉、操作咖啡机、整理物品等,帮助实现家庭自动化。工业自动化:在制造业中,Gen2Act能执行复杂的装配任务,或者在需要灵活性和适应性的环境中替换或辅助人工操作。服务行业:在餐饮或零售服务中,Gen2Act指导机器人完成点单、上菜、整理货架等任务。医疗辅助:在医疗领域,Gen2Act帮助开发执行精细操作的机器人,如协助手术或递送医疗用品。灾难救援:在灾难救援现场,Gen2Act操控机器人在未知环境中进行搜索和救援任务。