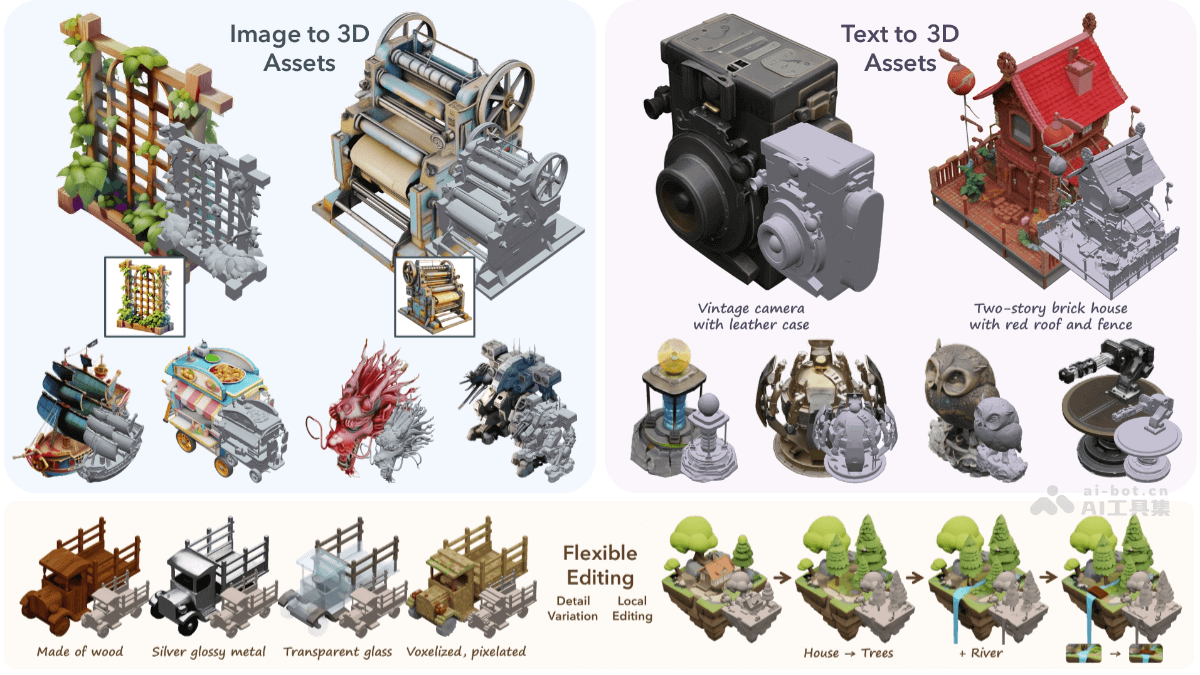
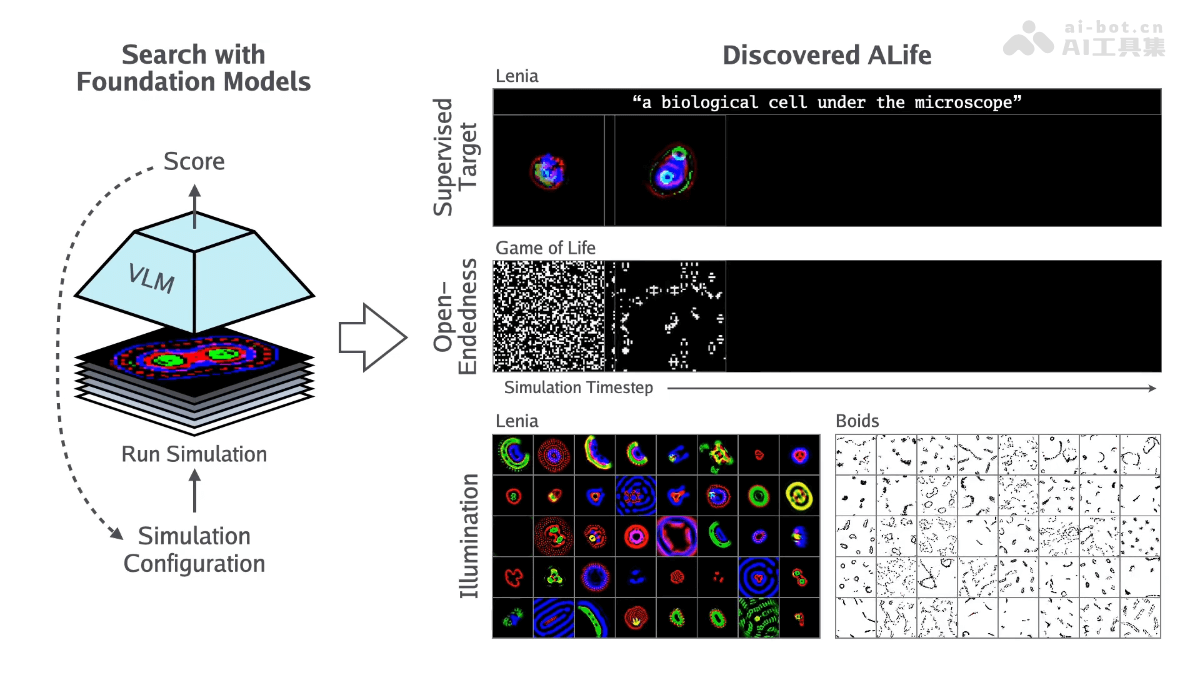
DisPose是北京大学、中国科学技术大学、清华大学和香港科技大学的研究团队共同推出的,提高人物图像动画质量的控制技术,基于从骨骼姿态和参考图像中提取有效的控制信号,无需额外的密集输入。DisPose将姿态控制分解为运动场引导和关键点对应,生成密集运动场以提供区域级引导,同时保持对不同体型的泛化能力。DisPose包括一个即插即用的混合ControlNet,能改善现有模型生成视频的质量和一致性。
 DisPose的主要功能运动场引导:从骨骼姿态生成密集运动场,提供区域级的密集引导,增强视频生成中的动作一致性。关键点对应:提取与参考图像中姿态关键点对应的扩散特征,将扩散特征转移到目标姿态,保持身份信息的一致性。即插即用模块:作为插件模块,支持无缝集成到现有的人物图像动画模型中,无需修改现有模型参数。质量与一致性提升:混合ControlNet改善生成视频的质量和外观一致性。无需额外密集输入:在不依赖于额外密集输入(如深度图)的情况下工作,减少对参考角色和驱动视频之间身体形状差异的敏感性。DisPose的技术原理运动场估计:稀疏运动场:DWpose估计骨骼姿态,基于关键点追踪运动位移,表示为轨迹图。密集运动场:条件运动传播(CMP)基于稀疏运动场和参考图像预测密集运动场,提供更细致的运动信号。关键点特征提取:用预训练的图像扩散模型提取参考图像的DIFT特征,并将这些特征与关键点对应起来,形成关键点特征图。混合ControlNet:设计了混合ControlNet,在训练期间更新,不需要冻结现有模型的其他部分,便于将运动场引导和关键点对应无缝集成到现有动画模型中。特征融合:基于特征融合层将稀疏和密集运动特征结合起来,生成最终的运动场引导信号。基于多尺度点编码器将关键点特征与U-Net编码器的中间特征相结合,增强特征的语义对应。控制信号集成:将运动场引导和关键点对应作为额外的控制信号,注入到潜在的视频扩散模型中,生成准确的人物图像动画。DisPose的项目地址项目官网:lihxxx.github.io/DisPoseGitHub仓库:https://github.com/lihxxx/DisPosearXiv技术论文:https://arxiv.org/pdf/2412.09349DisPose的应用场景艺术创作:艺术家创作出具有特定动作和表情的动态艺术作品,如动态绘画和数字雕塑。社交媒体:在社交媒体平台上,生成个性化的动态头像或者动态表情,增加互动的趣味性。数字人和虚拟偶像:创建和控制虚拟角色的动作和表情,应用于直播、视频会议或者作为虚拟偶像进行表演。电影制作:在电影后期制作中,生成或修改角色的动作,提高制作效率。虚拟现实(VR)和增强现实(AR):在VR和AR应用中,生成与用户互动的虚拟角色,提供更加自然和逼真的互动体验。
DisPose的主要功能运动场引导:从骨骼姿态生成密集运动场,提供区域级的密集引导,增强视频生成中的动作一致性。关键点对应:提取与参考图像中姿态关键点对应的扩散特征,将扩散特征转移到目标姿态,保持身份信息的一致性。即插即用模块:作为插件模块,支持无缝集成到现有的人物图像动画模型中,无需修改现有模型参数。质量与一致性提升:混合ControlNet改善生成视频的质量和外观一致性。无需额外密集输入:在不依赖于额外密集输入(如深度图)的情况下工作,减少对参考角色和驱动视频之间身体形状差异的敏感性。DisPose的技术原理运动场估计:稀疏运动场:DWpose估计骨骼姿态,基于关键点追踪运动位移,表示为轨迹图。密集运动场:条件运动传播(CMP)基于稀疏运动场和参考图像预测密集运动场,提供更细致的运动信号。关键点特征提取:用预训练的图像扩散模型提取参考图像的DIFT特征,并将这些特征与关键点对应起来,形成关键点特征图。混合ControlNet:设计了混合ControlNet,在训练期间更新,不需要冻结现有模型的其他部分,便于将运动场引导和关键点对应无缝集成到现有动画模型中。特征融合:基于特征融合层将稀疏和密集运动特征结合起来,生成最终的运动场引导信号。基于多尺度点编码器将关键点特征与U-Net编码器的中间特征相结合,增强特征的语义对应。控制信号集成:将运动场引导和关键点对应作为额外的控制信号,注入到潜在的视频扩散模型中,生成准确的人物图像动画。DisPose的项目地址项目官网:lihxxx.github.io/DisPoseGitHub仓库:https://github.com/lihxxx/DisPosearXiv技术论文:https://arxiv.org/pdf/2412.09349DisPose的应用场景艺术创作:艺术家创作出具有特定动作和表情的动态艺术作品,如动态绘画和数字雕塑。社交媒体:在社交媒体平台上,生成个性化的动态头像或者动态表情,增加互动的趣味性。数字人和虚拟偶像:创建和控制虚拟角色的动作和表情,应用于直播、视频会议或者作为虚拟偶像进行表演。电影制作:在电影后期制作中,生成或修改角色的动作,提高制作效率。虚拟现实(VR)和增强现实(AR):在VR和AR应用中,生成与用户互动的虚拟角色,提供更加自然和逼真的互动体验。