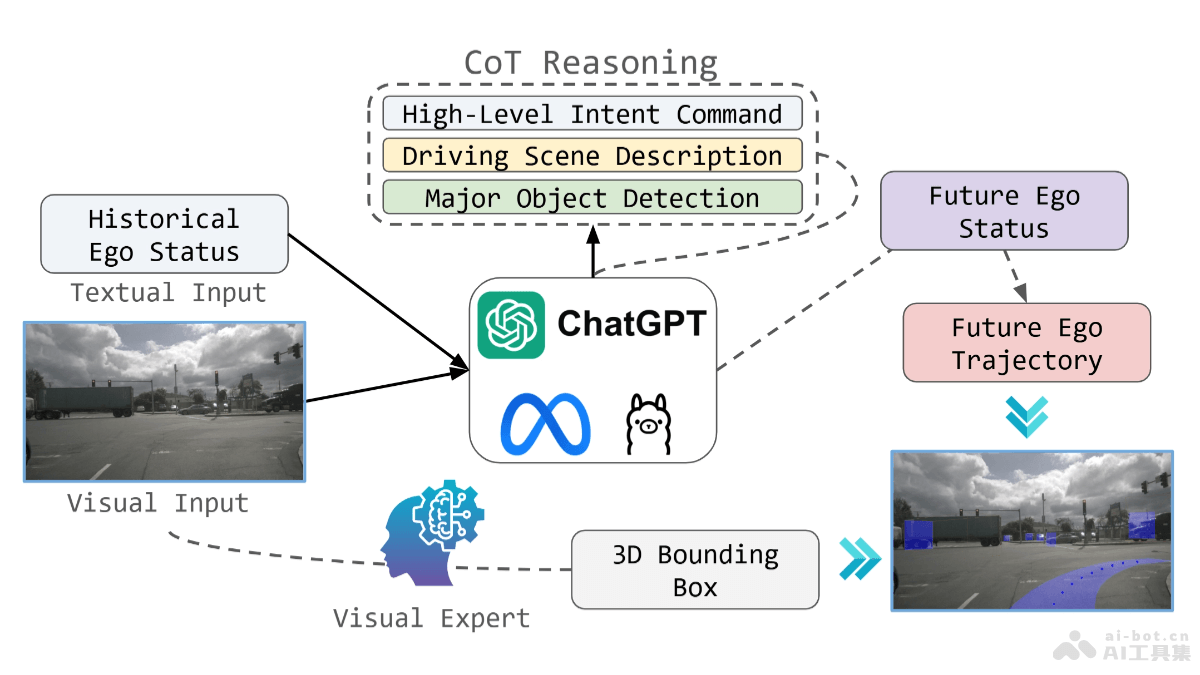
CLEAR是新加坡国立大学推出新型线性注意力机制,能提升预训练扩散变换器(DiTs)生成高分辨率图像的效率。基于将每个查询的注意力限制在局部窗口内,CLEAR实现了对图像分辨率的线性复杂度,降低了计算成本。实验表明,CLEAR在10K次迭代微调后,能在保持与原始模型相似性能的同时,减少99.5%的注意力计算,并在生成8K图像时提速6.3倍。CLEAR支持跨模型和插件的零样本泛化,及多GPU并行推理,增强模型的适用性和扩展性。
 CLEAR的主要功能线性复杂度:通过局部注意力机制将预训练DiTs的复杂度从二次降低到线性,适用于高分辨率图像生成。效率提升:在生成高分辨率图像时,显著减少计算量和时间延迟,加速图像生成过程。知识转移:通过少量的微调,能有效地从预训练模型转移知识到学生模型,保持生成质量。跨分辨率泛化:CLEAR展现出良好的跨分辨率泛化能力,能处理不同尺寸的图像生成任务。跨模型/插件泛化:CLEAR训练得到的注意力层能零样本泛化到其他模型和插件,无需额外适配。多GPU并行推理:CLEAR支持多GPU并行推理,优化大规模图像生成的效率和扩展性。CLEAR的技术原理局部注意力窗口:将每个查询(query)的限制在局部窗口内,仅与窗口内的键值(key-value)进行交互,实现线性复杂度。圆形窗口设计:与传统的正方形滑动窗口不同,CLEAR采用圆形窗口,考虑每个查询的欧几里得距离内的所有键值。知识蒸馏:在微调过程中,CLEAR用知识蒸馏目标,基于流匹配损失和预测/注意力输出一致性损失,减少线性化模型与原始模型之间的差异。多GPU并行推理优化:CLEAR基于局部注意力的局部性,减少多GPU并行推理时的通信开销,提高大规模图像生成的效率。保持原始功能:尽管每个查询仅访问局部信息,但通过堆叠多个Transformer块,每个令牌(token)能逐步捕获整体信息,类似于卷积神经网络的操作。稀疏注意力实现:作为一种稀疏注意力机制,能在GPU上高效实现,并利用底层优化。CLEAR的项目地址GitHub仓库:https://github.com/Huage001/CLEARarXiv技术论文:https://arxiv.org/pdf/2412.16112CLEAR的应用场景数字媒体创作:艺术家和设计师快速生成高分辨率的图像和艺术作品,提高创作效率。虚拟现实(VR)和增强现实(AR):在VR和AR应用中,用在实时生成高分辨率的虚拟环境和对象,提升用户体验。游戏开发:游戏开发者生成高质量的游戏资产和背景,减少开发时间和资源消耗。电影和视频制作:在电影和视频制作中,用在生成高分辨率的特效图像和动画,提高后期制作的效率。广告和营销:营销人员快速生成吸引人的广告图像和视觉内容,吸引潜在客户。
CLEAR的主要功能线性复杂度:通过局部注意力机制将预训练DiTs的复杂度从二次降低到线性,适用于高分辨率图像生成。效率提升:在生成高分辨率图像时,显著减少计算量和时间延迟,加速图像生成过程。知识转移:通过少量的微调,能有效地从预训练模型转移知识到学生模型,保持生成质量。跨分辨率泛化:CLEAR展现出良好的跨分辨率泛化能力,能处理不同尺寸的图像生成任务。跨模型/插件泛化:CLEAR训练得到的注意力层能零样本泛化到其他模型和插件,无需额外适配。多GPU并行推理:CLEAR支持多GPU并行推理,优化大规模图像生成的效率和扩展性。CLEAR的技术原理局部注意力窗口:将每个查询(query)的限制在局部窗口内,仅与窗口内的键值(key-value)进行交互,实现线性复杂度。圆形窗口设计:与传统的正方形滑动窗口不同,CLEAR采用圆形窗口,考虑每个查询的欧几里得距离内的所有键值。知识蒸馏:在微调过程中,CLEAR用知识蒸馏目标,基于流匹配损失和预测/注意力输出一致性损失,减少线性化模型与原始模型之间的差异。多GPU并行推理优化:CLEAR基于局部注意力的局部性,减少多GPU并行推理时的通信开销,提高大规模图像生成的效率。保持原始功能:尽管每个查询仅访问局部信息,但通过堆叠多个Transformer块,每个令牌(token)能逐步捕获整体信息,类似于卷积神经网络的操作。稀疏注意力实现:作为一种稀疏注意力机制,能在GPU上高效实现,并利用底层优化。CLEAR的项目地址GitHub仓库:https://github.com/Huage001/CLEARarXiv技术论文:https://arxiv.org/pdf/2412.16112CLEAR的应用场景数字媒体创作:艺术家和设计师快速生成高分辨率的图像和艺术作品,提高创作效率。虚拟现实(VR)和增强现实(AR):在VR和AR应用中,用在实时生成高分辨率的虚拟环境和对象,提升用户体验。游戏开发:游戏开发者生成高质量的游戏资产和背景,减少开发时间和资源消耗。电影和视频制作:在电影和视频制作中,用在生成高分辨率的特效图像和动画,提高后期制作的效率。广告和营销:营销人员快速生成吸引人的广告图像和视觉内容,吸引潜在客户。