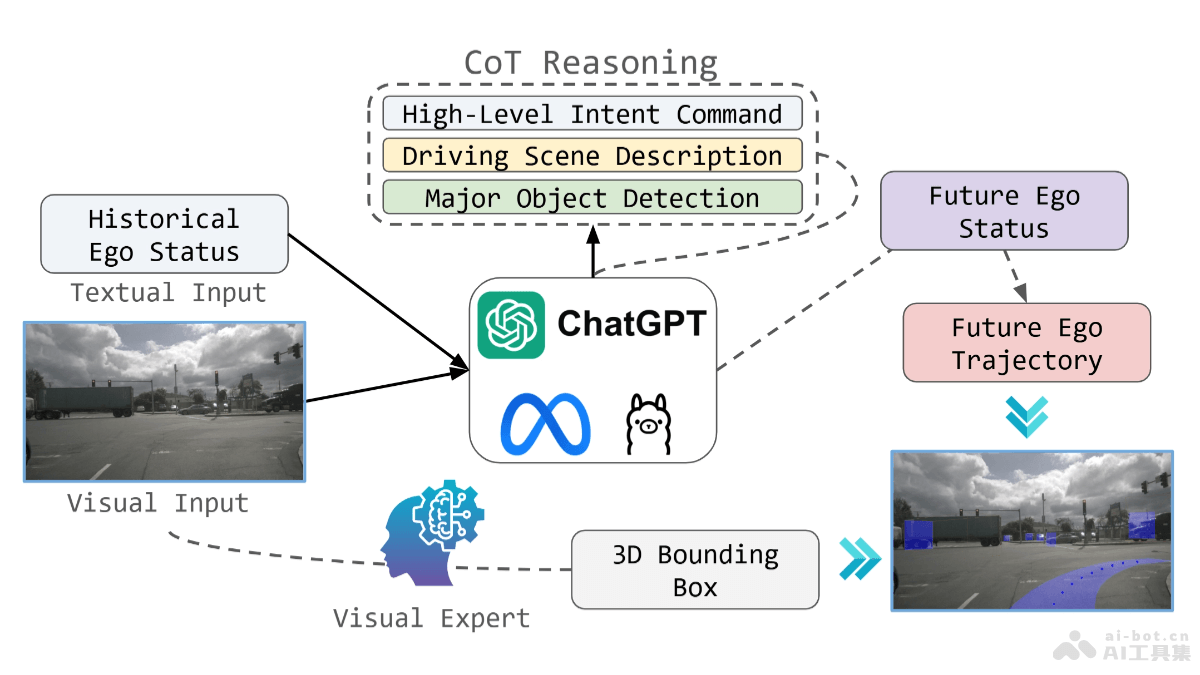
The Language of Motion是斯坦福大学李飞飞团队推出的多模态语言模型,能整合人类动作中的言语和非言语语言。模型能处理文本、语音和动作数据,生成对应的目标模态,对于创建自然交流的虚拟角色至关重要。The Language of Motion在共同语音手势生成任务上展现卓越的性能,且相较于传统模型,训练时需要的数据量大大减少。模型能进行情感预测等新任务,从动作中识别情绪。The Language of Motion对于游戏、电影、虚拟现实等应用领域具有重大意义,推动了虚拟角色与人类自然交流技术的发展。
 The Language of Motion的主要功能多模态输入处理:能接受文本、语音和动作数据作为输入,灵活处理多种模态的数据。动作理解和生成:基于输入的语音、文本或动作数据,理解和生成相应的3D人体动作。共同语音手势生成:生成与语音同步的手势,提升虚拟角色的自然交流能力。情感预测:从动作数据中预测情感,为心理健康、精神病学等领域提供支持。编辑手势生成:支持用户根据语音或文本提示编辑特定身体部位的动作,增强动作的表达性。The Language of Motion的技术原理模态标记化:将面部、手部、上身、下身的动作分别基于向量量化变分自编码器(VQ-VAE)标记化,将连续的动作数据转换为离散的标记(tokens)。多模态词汇表:将不同模态的标记组合成一个统一的多模态词汇表,让语言模型处理不同模态的输入。编码器-解码器架构:用编码器-解码器结构的语言模型,输入混合标记并生成输出标记序列。生成预训练:基于自我监督学习,对齐不同模态间的关系,如身体各部位动作的对应关系和音频-文本对齐。指令遵循训练:在预训练后,通过指令模板对模型进行微调,能根据自然语言指令执行特定的下游任务。端到端训练:模型在预训练和后期训练中均进行端到端训练,最大化模态间的对齐。The Language of Motion的项目地址项目官网:languageofmotion.github.ioarXiv技术论文:https://arxiv.org/pdf/2412.10523The Language of Motion的应用场景游戏开发:在游戏中创建更加真实和自然的非玩家角色(NPC),能够通过身体语言和手势与玩家进行更丰富的互动。电影和动画制作:在电影或动画中生成更加自然和流畅的3D角色动作,减少手动动画制作的工作量,提高生产效率。虚拟现实(VR):在虚拟现实环境中,提供更加真实的交互体验,让虚拟角色的动作和反应更加贴近真实人类。增强现实(AR):在AR应用中,让虚拟对象或角色的动作与现实世界中用户的手势和动作相协调。社交机器人:为社交机器人提供更自然的交流方式,增强机器人与人类的互动,使其在服务、教育或陪伴等领域更加有效。
The Language of Motion的主要功能多模态输入处理:能接受文本、语音和动作数据作为输入,灵活处理多种模态的数据。动作理解和生成:基于输入的语音、文本或动作数据,理解和生成相应的3D人体动作。共同语音手势生成:生成与语音同步的手势,提升虚拟角色的自然交流能力。情感预测:从动作数据中预测情感,为心理健康、精神病学等领域提供支持。编辑手势生成:支持用户根据语音或文本提示编辑特定身体部位的动作,增强动作的表达性。The Language of Motion的技术原理模态标记化:将面部、手部、上身、下身的动作分别基于向量量化变分自编码器(VQ-VAE)标记化,将连续的动作数据转换为离散的标记(tokens)。多模态词汇表:将不同模态的标记组合成一个统一的多模态词汇表,让语言模型处理不同模态的输入。编码器-解码器架构:用编码器-解码器结构的语言模型,输入混合标记并生成输出标记序列。生成预训练:基于自我监督学习,对齐不同模态间的关系,如身体各部位动作的对应关系和音频-文本对齐。指令遵循训练:在预训练后,通过指令模板对模型进行微调,能根据自然语言指令执行特定的下游任务。端到端训练:模型在预训练和后期训练中均进行端到端训练,最大化模态间的对齐。The Language of Motion的项目地址项目官网:languageofmotion.github.ioarXiv技术论文:https://arxiv.org/pdf/2412.10523The Language of Motion的应用场景游戏开发:在游戏中创建更加真实和自然的非玩家角色(NPC),能够通过身体语言和手势与玩家进行更丰富的互动。电影和动画制作:在电影或动画中生成更加自然和流畅的3D角色动作,减少手动动画制作的工作量,提高生产效率。虚拟现实(VR):在虚拟现实环境中,提供更加真实的交互体验,让虚拟角色的动作和反应更加贴近真实人类。增强现实(AR):在AR应用中,让虚拟对象或角色的动作与现实世界中用户的手势和动作相协调。社交机器人:为社交机器人提供更自然的交流方式,增强机器人与人类的互动,使其在服务、教育或陪伴等领域更加有效。