TANGO 是一个由东京大学和 CyberAgent AI Lab 共同推出的开源框架,专注于生成与目标语音同步的全身手势视频。基于分层音频运动嵌入和扩散插值网络,将目标语音音频与参考视频库中的动作完美匹配,确保制作出高保真度、动作同步的视频。TANGO 技术突破极大地降低视频内容制作的成本,包含新闻播报、虚拟人解说和虚拟 YouTube 内容创作等领域,为用户提供一种高效且经济的解决方案。
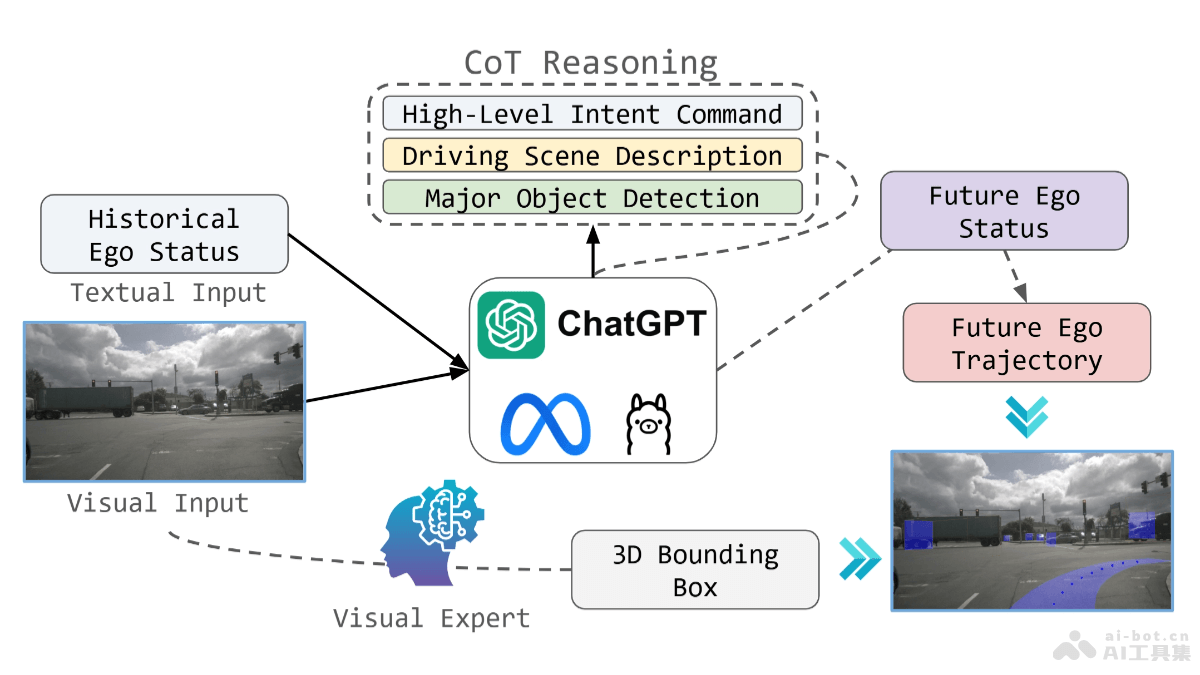
 TANGO的主要功能语音驱动的全身手势生成:根据目标语音音频生成与之同步的全身手势视频。高保真视频制作:确保生成的视频具有高保真度,动作自然且与语音内容精确匹配。跨模态对齐:基于分层音频运动嵌入技术,实现音频信号与视频动作之间的精准对齐。过渡帧生成:用扩散插值网络生成高质量的过渡帧,确保视频动作的连贯性。外观一致性保持:在生成的视频中保持与参考视频相同的人物外观和背景,避免视觉不一致的问题。TANGO的技术原理分层音频运动嵌入(AuMoCLIP):隐式的层次化音频-动作联合嵌入空间,用在编码配对的音频和动作数据。基于对比学习,将语音音频和动作数据映射到一个共同的潜在空间中,让匹配的音频和动作在空间中的距离更近,实现精准的动作检索。扩散插值网络(ACInterp):网络基于现有的视频生成扩散模型,用在生成高质量的过渡帧。包括一个参考运动模块和单应背景流,保持生成视频与参考视频间的外观一致性。有效消除传统基于流的插值方法中常见的模糊和重影伪影。动作图检索方法:TANGO基于学习的方法,而非简单的音频起始特征和关键词匹配,检索与目标语音音频最匹配的动作路径。能更好地处理不同说话者的动作与音频起始不同步的情况,及参考视频中缺少特定关键词的问题。图结构:TANGO用有向图结构来表示视频帧(节点)和之间有效的转换(边)。给定目标音频,系统提取时间特征,用时间特征检索视频播放路径的一个子集。当原始参考视频中不存在转换边时,用ACInterp生成平滑的过渡帧。TANGO的项目地址项目官网:pantomatrix.github.io/TANGOarXiv技术论文:https://arxiv.org/pdf/2410.04221在线体验Demo:https://huggingface.co/spaces/H-Liu1997/TANGOTANGO的应用场景新闻广播:生成与新闻稿同步的全身手势视频,提高新闻播报的自然度和观众的观看体验。虚拟YouTuber:为虚拟YouTuber创建与语音同步的全身动作视频,增强粉丝的互动和参与感。在线教育:制作教育内容时,基于TANGO生成教师的全身手势视频,让远程教学更加生动和有效。企业培训:在企业培训视频中加入与讲解同步的手势,提高学习材料的吸引力和信息的传达效率。视频会议:在视频会议中,用TANGO生成的手势视频提升参与者的交流体验,尤其是在远程协作时。
TANGO的主要功能语音驱动的全身手势生成:根据目标语音音频生成与之同步的全身手势视频。高保真视频制作:确保生成的视频具有高保真度,动作自然且与语音内容精确匹配。跨模态对齐:基于分层音频运动嵌入技术,实现音频信号与视频动作之间的精准对齐。过渡帧生成:用扩散插值网络生成高质量的过渡帧,确保视频动作的连贯性。外观一致性保持:在生成的视频中保持与参考视频相同的人物外观和背景,避免视觉不一致的问题。TANGO的技术原理分层音频运动嵌入(AuMoCLIP):隐式的层次化音频-动作联合嵌入空间,用在编码配对的音频和动作数据。基于对比学习,将语音音频和动作数据映射到一个共同的潜在空间中,让匹配的音频和动作在空间中的距离更近,实现精准的动作检索。扩散插值网络(ACInterp):网络基于现有的视频生成扩散模型,用在生成高质量的过渡帧。包括一个参考运动模块和单应背景流,保持生成视频与参考视频间的外观一致性。有效消除传统基于流的插值方法中常见的模糊和重影伪影。动作图检索方法:TANGO基于学习的方法,而非简单的音频起始特征和关键词匹配,检索与目标语音音频最匹配的动作路径。能更好地处理不同说话者的动作与音频起始不同步的情况,及参考视频中缺少特定关键词的问题。图结构:TANGO用有向图结构来表示视频帧(节点)和之间有效的转换(边)。给定目标音频,系统提取时间特征,用时间特征检索视频播放路径的一个子集。当原始参考视频中不存在转换边时,用ACInterp生成平滑的过渡帧。TANGO的项目地址项目官网:pantomatrix.github.io/TANGOarXiv技术论文:https://arxiv.org/pdf/2410.04221在线体验Demo:https://huggingface.co/spaces/H-Liu1997/TANGOTANGO的应用场景新闻广播:生成与新闻稿同步的全身手势视频,提高新闻播报的自然度和观众的观看体验。虚拟YouTuber:为虚拟YouTuber创建与语音同步的全身动作视频,增强粉丝的互动和参与感。在线教育:制作教育内容时,基于TANGO生成教师的全身手势视频,让远程教学更加生动和有效。企业培训:在企业培训视频中加入与讲解同步的手势,提高学习材料的吸引力和信息的传达效率。视频会议:在视频会议中,用TANGO生成的手势视频提升参与者的交流体验,尤其是在远程协作时。