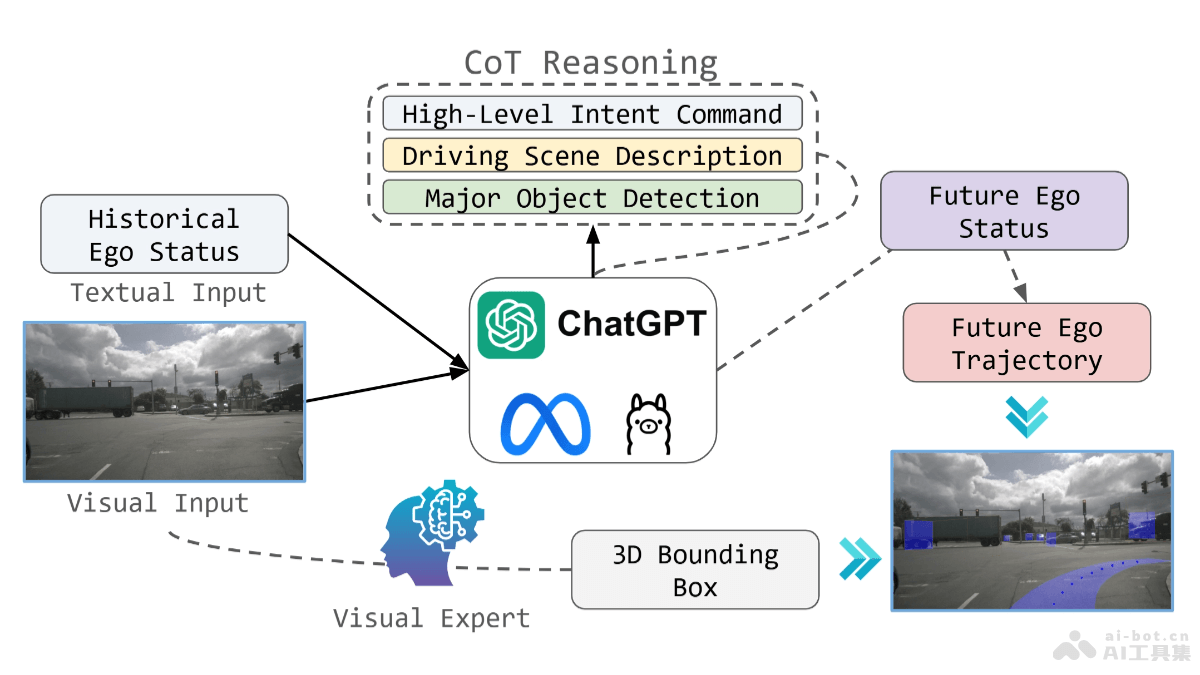
FineVideo是由Hugging Face推出的一个大型多模态视频数据集,专注于视频理解领域中的复杂任务,如情绪分析、故事叙述和媒体编辑。FineVideo包含超过43,000个YouTube视频,覆盖122个类别,总时长约3,425小时。每个视频有详细的元数据标注,包括场景、角色、剧情反转和视听关联等。FineVideo的独特之处在于捕捉视频的叙事和情感旅程,为AI模型提供丰富的上下文信息,更深入地理解视频内容。
 FineVideo的主要功能情绪分析:通过视频中的视觉和音频内容,分析和识别不同的情绪状态。故事叙述理解:理解视频中的叙事结构,包括情节发展、角色互动和关键转折点。媒体编辑:支持视频编辑任务,如视频摘要、剪辑和增强,改善叙事和观众体验。多模态学习:结合视频的视觉内容和音频轨道,进行深度学习和模式识别研究。场景分割:识别和分割视频中的不同场景,为内容分析提供基础。物体和角色识别:检测和跟踪视频中的对象和角色,以及它们的动作和交互。FineVideo的技术原理数据采集:从 YouTube 等平台收集视频数据,视频遵循知识共享署名(CC-BY)许可,确保数据的合法使用。视频预处理:对收集的视频进行技术处理,包括格式转换、分辨率调整、帧率统一等,便于后续的分析和处理。元数据提取:基于自动化工具从视频中提取元数据,如视频的分辨率、时长、标题、描述、标签等。时序标注:通过算法对视频内容进行时序分析,识别和标注视频中的关键场景、活动、对象出现和情绪变化等。多模态分析:结合视频的视觉内容和音频轨道,进行深度学习分析,理解视频的叙事和情感内容。FineVideo的项目地址HuggingFace模型库:https://huggingface.co/datasets/HuggingFaceFV/finevideoFineVideo的应用场景视频内容分析:自动标注和分类视频内容,包括场景识别、物体检测和跟踪。情绪分析:分析视频中人物的情绪状态,用于用户行为研究、影视内容分析等。故事叙述和剧情分析:理解视频叙事结构,用于电影、电视剧、纪录片等的分析和创作。媒体编辑和后期制作:辅助视频编辑工作,如自动剪辑、高光时刻提取、内容增强等。多模态学习:结合视频、音频和文本数据,进行深度学习模型的训练和优化。交互式媒体:在视频游戏中创建动态故事线,或在教育软件中提供互动式学习体验。
FineVideo的主要功能情绪分析:通过视频中的视觉和音频内容,分析和识别不同的情绪状态。故事叙述理解:理解视频中的叙事结构,包括情节发展、角色互动和关键转折点。媒体编辑:支持视频编辑任务,如视频摘要、剪辑和增强,改善叙事和观众体验。多模态学习:结合视频的视觉内容和音频轨道,进行深度学习和模式识别研究。场景分割:识别和分割视频中的不同场景,为内容分析提供基础。物体和角色识别:检测和跟踪视频中的对象和角色,以及它们的动作和交互。FineVideo的技术原理数据采集:从 YouTube 等平台收集视频数据,视频遵循知识共享署名(CC-BY)许可,确保数据的合法使用。视频预处理:对收集的视频进行技术处理,包括格式转换、分辨率调整、帧率统一等,便于后续的分析和处理。元数据提取:基于自动化工具从视频中提取元数据,如视频的分辨率、时长、标题、描述、标签等。时序标注:通过算法对视频内容进行时序分析,识别和标注视频中的关键场景、活动、对象出现和情绪变化等。多模态分析:结合视频的视觉内容和音频轨道,进行深度学习分析,理解视频的叙事和情感内容。FineVideo的项目地址HuggingFace模型库:https://huggingface.co/datasets/HuggingFaceFV/finevideoFineVideo的应用场景视频内容分析:自动标注和分类视频内容,包括场景识别、物体检测和跟踪。情绪分析:分析视频中人物的情绪状态,用于用户行为研究、影视内容分析等。故事叙述和剧情分析:理解视频叙事结构,用于电影、电视剧、纪录片等的分析和创作。媒体编辑和后期制作:辅助视频编辑工作,如自动剪辑、高光时刻提取、内容增强等。多模态学习:结合视频、音频和文本数据,进行深度学习模型的训练和优化。交互式媒体:在视频游戏中创建动态故事线,或在教育软件中提供互动式学习体验。