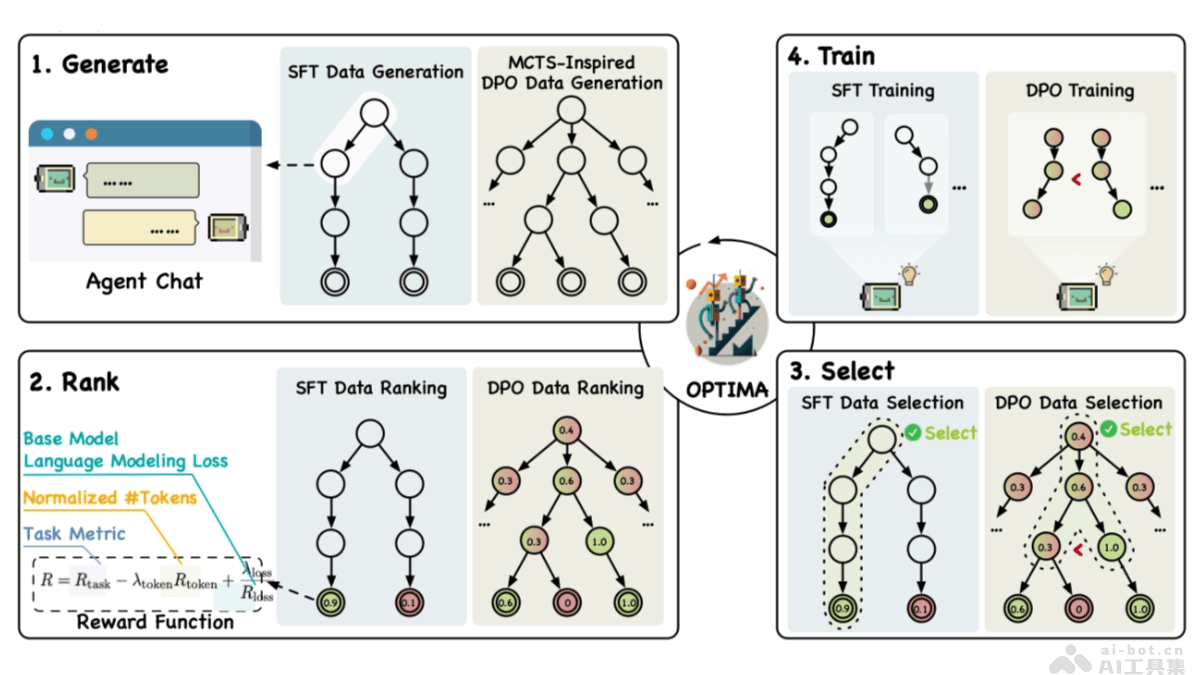
Self-Taught Evaluators是一种新型的模型评估方法,基于自我训练的方式提高大型语言模型(LLM)的评估能力,无需人工标注数据。从未经标记的指令开始,用迭代自我改进方案生成对比模型输出。用LLM作为裁判,生成推理轨迹和最终判断。在每次迭代中重复,用改进的预测训练模型。在实验中,Self-Taught Evaluators提高基于Llama3-70B-Instruct模型的评估准确性,从75.4提高到88.3,在多数投票的情况下达到88.7,超越常用的LLM裁判如GPT-4,与用人工标注数据训练的顶级奖励模型性能相当。
 Self-Taught Evaluators的主要功能生成对比模型输出:从未经标记的指令开始,基于提示生成不同质量的模型响应对。训练LLM作为裁判:用LLM生成推理轨迹和最终判断,评估哪一响应更优。迭代自我改进:在每次迭代中用当前模型的判断标注训练数据,微调模型,实现自我改进。评估模型性能:在标准评估协议如RewardBench上评估模型的准确性,与人类评估结果进行比较。Self-Taught Evaluators的技术原理初始化:假设访问大量人类编写的用户指令和一个初始的种子LLM。指令选择:基于LLM对指令进行分类,选择具有挑战性和平衡分布的指令子集。响应对构建:为每个选定的指令生成偏好数据,包括两个响应(优选和非优选),基于提示生成,确保非优选响应的质量低于优选响应。迭代训练:包括判断注释和模型微调两个步骤。用当前模型生成推理轨迹和判断,如果判断正确则将示例添加到训练集中。用数据微调模型,为下一次迭代提供更新的模型。Self-Taught Evaluators的项目地址GitHub仓库:https://github.com/facebookresearch/RAM/tree/main/projects/self_taught_evaluatorHuggingFace模型库:https://huggingface.co/datasets/facebook/Self-taught-evaluator-DPO-dataarXiv技术论文:https://arxiv.org/pdf/2408.02666Self-Taught Evaluators的应用场景语言模型开发:在开发新型的大型语言模型(LLM)时,Self-Taught Evaluators评估和优化模型的输出质量,确保模型生成的文本符合预期的标准。自动化内容评估:在内容生产领域,如新闻机构、出版业或社交媒体平台,用在自动化评估内容的质量和准确性,提高内容审核的效率。教育和学术研究:在教育领域,Self-Taught Evaluators作为辅助工具,帮助评估学生的写作作业或研究论文,提供反馈和改进建议。客服和技术支持:在客户服务领域,用在评估自动回复系统的质量,确保回复既准确又有帮助,提升客户满意度。编程和代码生成:对于需要代码生成和评估的场景,Self-Taught Evaluators能评估生成的代码片段的质量,帮助开发人员改进代码。
Self-Taught Evaluators的主要功能生成对比模型输出:从未经标记的指令开始,基于提示生成不同质量的模型响应对。训练LLM作为裁判:用LLM生成推理轨迹和最终判断,评估哪一响应更优。迭代自我改进:在每次迭代中用当前模型的判断标注训练数据,微调模型,实现自我改进。评估模型性能:在标准评估协议如RewardBench上评估模型的准确性,与人类评估结果进行比较。Self-Taught Evaluators的技术原理初始化:假设访问大量人类编写的用户指令和一个初始的种子LLM。指令选择:基于LLM对指令进行分类,选择具有挑战性和平衡分布的指令子集。响应对构建:为每个选定的指令生成偏好数据,包括两个响应(优选和非优选),基于提示生成,确保非优选响应的质量低于优选响应。迭代训练:包括判断注释和模型微调两个步骤。用当前模型生成推理轨迹和判断,如果判断正确则将示例添加到训练集中。用数据微调模型,为下一次迭代提供更新的模型。Self-Taught Evaluators的项目地址GitHub仓库:https://github.com/facebookresearch/RAM/tree/main/projects/self_taught_evaluatorHuggingFace模型库:https://huggingface.co/datasets/facebook/Self-taught-evaluator-DPO-dataarXiv技术论文:https://arxiv.org/pdf/2408.02666Self-Taught Evaluators的应用场景语言模型开发:在开发新型的大型语言模型(LLM)时,Self-Taught Evaluators评估和优化模型的输出质量,确保模型生成的文本符合预期的标准。自动化内容评估:在内容生产领域,如新闻机构、出版业或社交媒体平台,用在自动化评估内容的质量和准确性,提高内容审核的效率。教育和学术研究:在教育领域,Self-Taught Evaluators作为辅助工具,帮助评估学生的写作作业或研究论文,提供反馈和改进建议。客服和技术支持:在客户服务领域,用在评估自动回复系统的质量,确保回复既准确又有帮助,提升客户满意度。编程和代码生成:对于需要代码生成和评估的场景,Self-Taught Evaluators能评估生成的代码片段的质量,帮助开发人员改进代码。