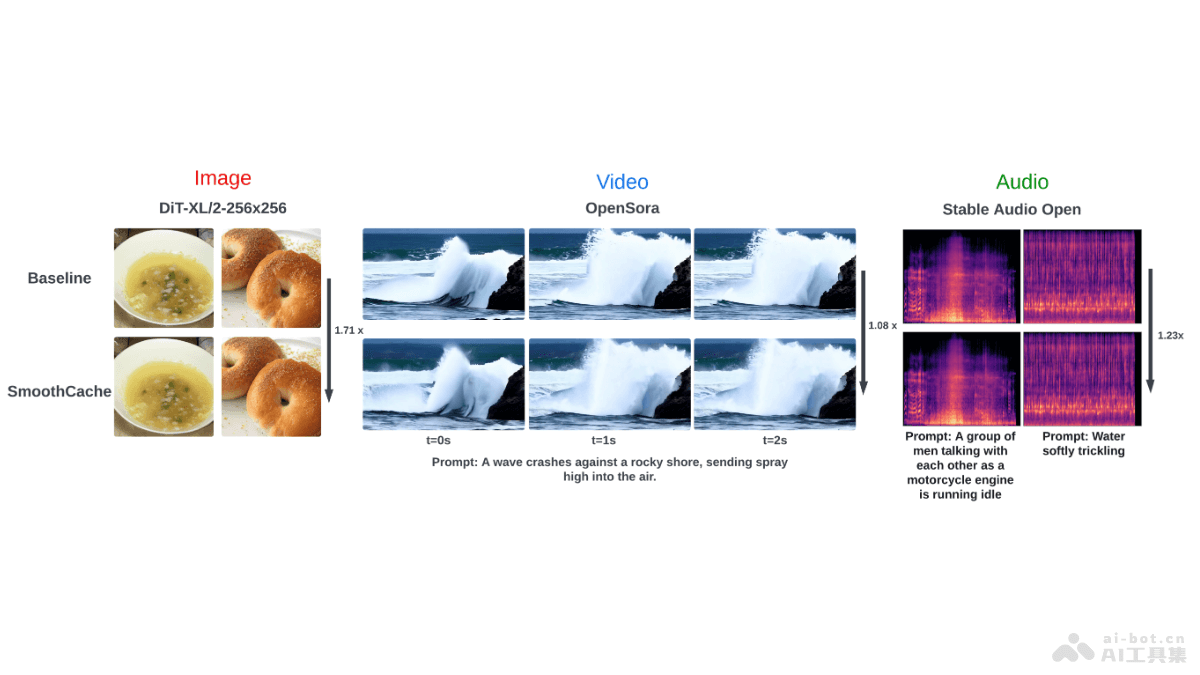
mPLUG-DocOwl 1.5是由阿里巴巴集团推出的多模态大型语言模型,专注于OCR-free(无需光学字符识别)的文档理解。模型基于统一结构学习,强化对文本丰富图像如文档、表格和图表的结构信息理解能力。mPLUG-DocOwl 1.5包含结构感知解析任务和多粒度文本定位任务,覆盖五个领域:文档、网页、表格、图表和自然图像。mPLUG-DocOwl 1.5的H-Reducer模块基于卷积层合并水平相邻图像块,减少视觉特征长度,保持布局信息,让模型能高效处理高分辨率图像。在多个视觉文档理解基准测试中,模型展现业界领先的无OCR性能,提升SOTA性能超过10分。
 mPLUG-DocOwl 1.5的主要功能结构感知的文档解析:识别和解析文档中的文本结构,如换行和空格,理解文档的组织方式。表格转Markdown:将表格图像转换为Markdown格式,便于进一步的处理和阅读。图表转Markdown:将图表图像转换为Markdown格式,保留图表中的关键数据和结构信息。自然图像解析:对自然场景中的图像进行解析,识别和理解图像中的文字信息。多粒度文本定位:在不同粒度级别(单词、短语、行、块)上定位文本,增强模型对文本位置的识别能力。mPLUG-DocOwl 1.5的技术原理统一结构学习(Unified Structure Learning):基于结构感知解析任务和多粒度文本定位任务,模型学习如何理解和处理文本丰富的图像。H-Reducer视觉-文本模块:基于卷积层合并水平相邻的视觉特征,减少特征长度,保持布局信息,让大型语言模型能更有效地处理高分辨率图像。多模态大型语言模型(MLLM):结合视觉编码器和大型语言模型,用视觉到文本的模块(如H-Reducer),让模型理解和生成与视觉内容相关的语言描述。大规模数据集训练:用大规模的标注数据集,如DocStruct4M和DocReason25K,模型能学习各种文档和图像中的文本结构和语义信息。两阶段训练框架:首先进行统一结构学习,然后进行多任务调整,让模型在各种下游任务中能表现出色。mPLUG-DocOwl 1.5的项目地址GitHub仓库:X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5arXiv技术论文:https://arxiv.org/pdf/2403.12895mPLUG-DocOwl 1.5的应用场景自动化文档处理:在企业或政府机构中,自动化解析和理解大量文档,如合同、发票、报告和表格,提高工作效率和减少人工干预。智能搜索引擎:在搜索引擎中集成mPLUG-DocOwl 1.5,增强对图像中文本内容的搜索能力,提供更准确的搜索结果。辅助阅读和理解:帮助用户更好地理解复杂文档的内容,尤其是对于视觉障碍人士,基于解析文档结构提供易于访问的信息。教育和学术研究:在教育领域,辅助学生和研究人员理解教科书、学术论文和研究资料中的复杂信息。客户服务和支持:在客户服务系统中,用mPLUG-DocOwl 1.5解析用户上传的文档,自动提取关键信息,提供更快的服务响应。
mPLUG-DocOwl 1.5的主要功能结构感知的文档解析:识别和解析文档中的文本结构,如换行和空格,理解文档的组织方式。表格转Markdown:将表格图像转换为Markdown格式,便于进一步的处理和阅读。图表转Markdown:将图表图像转换为Markdown格式,保留图表中的关键数据和结构信息。自然图像解析:对自然场景中的图像进行解析,识别和理解图像中的文字信息。多粒度文本定位:在不同粒度级别(单词、短语、行、块)上定位文本,增强模型对文本位置的识别能力。mPLUG-DocOwl 1.5的技术原理统一结构学习(Unified Structure Learning):基于结构感知解析任务和多粒度文本定位任务,模型学习如何理解和处理文本丰富的图像。H-Reducer视觉-文本模块:基于卷积层合并水平相邻的视觉特征,减少特征长度,保持布局信息,让大型语言模型能更有效地处理高分辨率图像。多模态大型语言模型(MLLM):结合视觉编码器和大型语言模型,用视觉到文本的模块(如H-Reducer),让模型理解和生成与视觉内容相关的语言描述。大规模数据集训练:用大规模的标注数据集,如DocStruct4M和DocReason25K,模型能学习各种文档和图像中的文本结构和语义信息。两阶段训练框架:首先进行统一结构学习,然后进行多任务调整,让模型在各种下游任务中能表现出色。mPLUG-DocOwl 1.5的项目地址GitHub仓库:X-PLUG/mPLUG-DocOwl/tree/main/DocOwl1.5arXiv技术论文:https://arxiv.org/pdf/2403.12895mPLUG-DocOwl 1.5的应用场景自动化文档处理:在企业或政府机构中,自动化解析和理解大量文档,如合同、发票、报告和表格,提高工作效率和减少人工干预。智能搜索引擎:在搜索引擎中集成mPLUG-DocOwl 1.5,增强对图像中文本内容的搜索能力,提供更准确的搜索结果。辅助阅读和理解:帮助用户更好地理解复杂文档的内容,尤其是对于视觉障碍人士,基于解析文档结构提供易于访问的信息。教育和学术研究:在教育领域,辅助学生和研究人员理解教科书、学术论文和研究资料中的复杂信息。客户服务和支持:在客户服务系统中,用mPLUG-DocOwl 1.5解析用户上传的文档,自动提取关键信息,提供更快的服务响应。