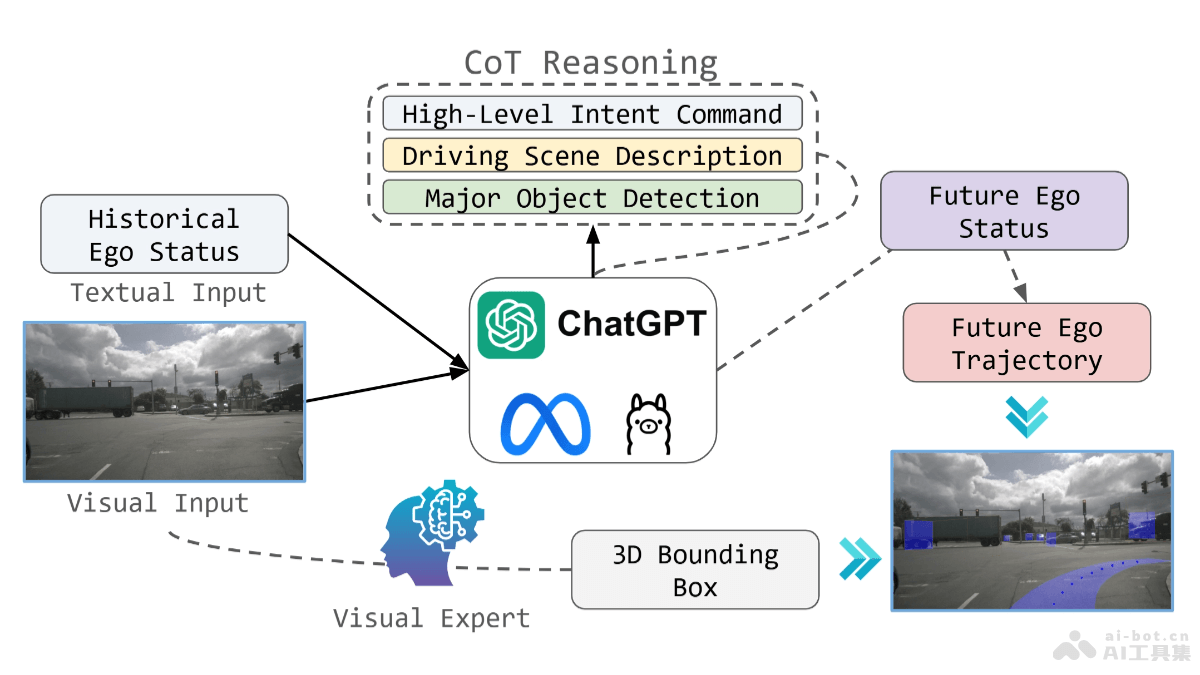
SCoRe(Self-Correction via Reinforcement Learning)是谷歌DeepMind推出的一种创新的多轮强化学习方法,旨在提高大型语言模型(LLM)的自我纠错能力。通过在模型生成的数据上进行训练,使模型在没有外部指导的情况下,对错误答案进行自我纠正。SCoRe的训练包括两个阶段:第一阶段通过适当的正则化约束来初始化模型,避免在训练过程中出现模式崩溃;第二阶段通过奖励机制鼓励模型在第二次尝试中进行有效的自我纠正。实验结果表明,SCoRe在数学问题和编程任务上的自我纠正能力分别提升15.6%和9.1%,优于传统的监督学习方法。SCoRe的成功展示强化学习在提升大模型性能方面的潜力,尤其是在需要高度准确率的应用场景中。
 SCoRe的主要功能自我纠错:SCoRe使大型语言模型在没有外部反馈的情况下识别并纠正自己的错误。自生成数据训练:基于模型自己生成的数据进行训练,不依赖外部标注或教师模型。性能提升:在数学和编程任务中,提高模型的自我纠错能力。多轮学习:通过多轮尝试逐步改进答案,达到最佳响应。适应性强:能适应训练和推理之间数据分布的差异。SCoRe的技术原理多轮强化学习:SCoRe基于多轮RL框架,让模型在多个连续的尝试中学习如何改进行为。正则化约束:在模型的第一次尝试中用正则化技术,如KL散度,保持输出的稳定性。奖励塑造:通过设计奖励函数鼓励模型在后续尝试中进行有效的自我纠正。策略初始化:在训练的第一阶段,通过特定的策略初始化提高模型的自我纠错能力。避免分布不匹配:SCoRe通过在自生成数据上训练,避免训练数据与模型实际响应分布之间的不匹配问题。增量学习:模型在每次尝试中都尝试基于之前的输出进行改进,实现增量学习。SCoRe的项目地址arXiv技术论文:https://arxiv.org/pdf/2409.12917SCoRe的应用场景数学问题求解:在数学领域,模型要进行复杂的计算和逻辑推理。SCoRe帮助模型在给出错误答案后进行自我纠错,提高解题的准确率。编程和代码生成:在编程任务中,代码的正确性至关重要。SCoRe能指导模型修正代码中的错误,提高代码的可靠性。法律文档分析:法律领域中的文档分析需要极高的准确率。SCoRe帮助模型在解读法律条文和案例时进行自我纠错。金融报告生成:金融报告中的错误会导致严重后果。SCoRe确保模型在生成报告时的准确性。医疗诊断辅助:在医疗领域,模型的自我纠错能力帮助提高诊断的准确性,减少误诊的风险。
SCoRe的主要功能自我纠错:SCoRe使大型语言模型在没有外部反馈的情况下识别并纠正自己的错误。自生成数据训练:基于模型自己生成的数据进行训练,不依赖外部标注或教师模型。性能提升:在数学和编程任务中,提高模型的自我纠错能力。多轮学习:通过多轮尝试逐步改进答案,达到最佳响应。适应性强:能适应训练和推理之间数据分布的差异。SCoRe的技术原理多轮强化学习:SCoRe基于多轮RL框架,让模型在多个连续的尝试中学习如何改进行为。正则化约束:在模型的第一次尝试中用正则化技术,如KL散度,保持输出的稳定性。奖励塑造:通过设计奖励函数鼓励模型在后续尝试中进行有效的自我纠正。策略初始化:在训练的第一阶段,通过特定的策略初始化提高模型的自我纠错能力。避免分布不匹配:SCoRe通过在自生成数据上训练,避免训练数据与模型实际响应分布之间的不匹配问题。增量学习:模型在每次尝试中都尝试基于之前的输出进行改进,实现增量学习。SCoRe的项目地址arXiv技术论文:https://arxiv.org/pdf/2409.12917SCoRe的应用场景数学问题求解:在数学领域,模型要进行复杂的计算和逻辑推理。SCoRe帮助模型在给出错误答案后进行自我纠错,提高解题的准确率。编程和代码生成:在编程任务中,代码的正确性至关重要。SCoRe能指导模型修正代码中的错误,提高代码的可靠性。法律文档分析:法律领域中的文档分析需要极高的准确率。SCoRe帮助模型在解读法律条文和案例时进行自我纠错。金融报告生成:金融报告中的错误会导致严重后果。SCoRe确保模型在生成报告时的准确性。医疗诊断辅助:在医疗领域,模型的自我纠错能力帮助提高诊断的准确性,减少误诊的风险。