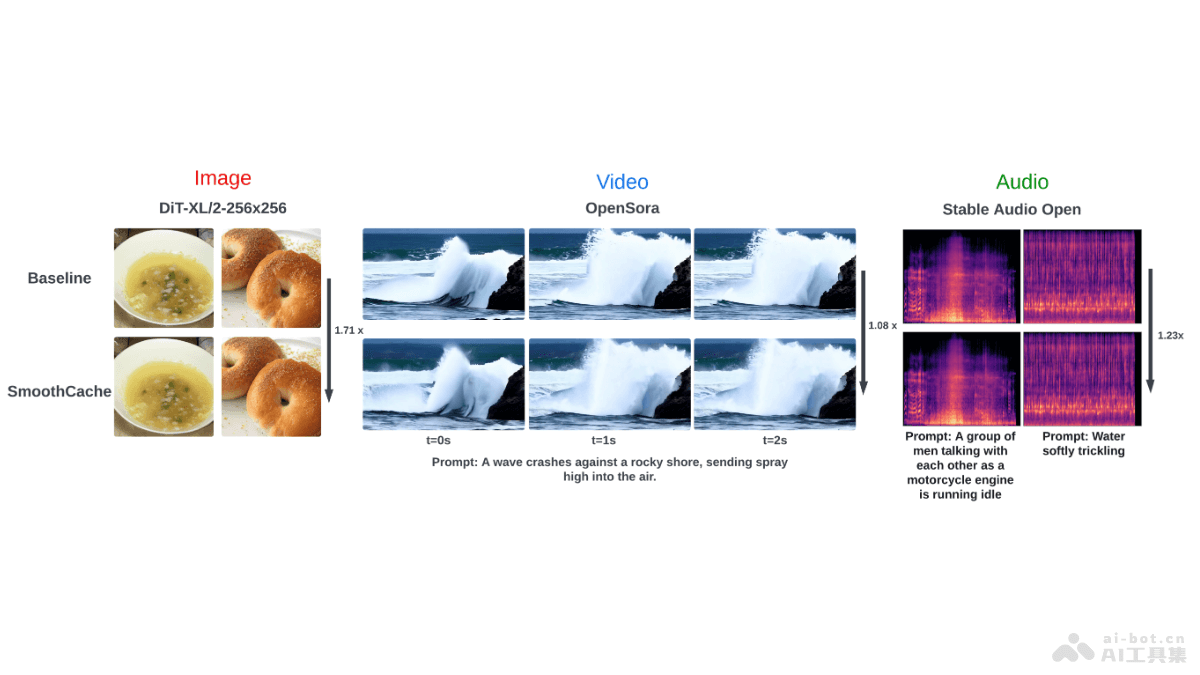
VideoTuna是集成多种AI视频生成模型的代码库,支持文本到视频、图像到视频和文本到图像的转换。VideoTuna提供预训练、持续训练、后训练对齐和微调等全面视频生成流程,支持U-Net和DiT架构,并计划推出3D视频VAE及可控面部视频生成模型。VideoTuna能简化视频内容生成,提高视频质量和可控性,降低技术门槛,让非专业人士也能轻松创作高质量视频。
 VideoTuna的主要功能多模型支持:集成多种AI视频生成模型,如U-Net和DiT架构,支持不同的视频生成任务。文本到视频生成:将文本描述直接转换为视频内容,实现创意的快速视觉化。图像到视频生成:基于静态图像生成视频,增加图像的动态表现力。文本到图像生成:将文本描述转换为图像,用于图像合成和编辑。预训练和微调:提供预训练模型,支持用户根据自己的数据进行微调,适应特定应用场景。VideoTuna的技术原理深度学习:VideoTuna基于深度学习技术,用神经网络学习视频内容的生成。生成对抗网络(GANs):用GANs生成视频,其中生成器网络创建视频,判别器网络评估视频的真实性。变分自编码器(VAEs):用VAEs学习视频数据的潜在表示,生成新的视频内容。注意力机制:用注意力机制来提高模型对视频内容特定部分的关注,提高生成的准确性和相关性。多模态学习:结合文本、图像和视频数据,让模型能理解和生成跨模态的内容。VideoTuna的项目地址GitHub仓库:https://github.com/VideoVerses/VideoTunaVideoTuna的应用场景内容创作:视频博主和内容创作者快速将创意文本或图像转换成视频,提高内容生产的效率和多样性。电影和视频制作:在电影制作中,生成特效场景或预览动画,减少实际拍摄的成本和时间。广告和营销:企业创建吸引人的广告视频,通过文本描述快速生成视频广告,提高营销效率。教育和培训:教育领域生成教学视频,将复杂的理论概念以视频形式直观展示,增强学习体验。新闻和报道:新闻机构快速生成新闻报道视频,提高新闻报道的时效性和吸引力。
VideoTuna的主要功能多模型支持:集成多种AI视频生成模型,如U-Net和DiT架构,支持不同的视频生成任务。文本到视频生成:将文本描述直接转换为视频内容,实现创意的快速视觉化。图像到视频生成:基于静态图像生成视频,增加图像的动态表现力。文本到图像生成:将文本描述转换为图像,用于图像合成和编辑。预训练和微调:提供预训练模型,支持用户根据自己的数据进行微调,适应特定应用场景。VideoTuna的技术原理深度学习:VideoTuna基于深度学习技术,用神经网络学习视频内容的生成。生成对抗网络(GANs):用GANs生成视频,其中生成器网络创建视频,判别器网络评估视频的真实性。变分自编码器(VAEs):用VAEs学习视频数据的潜在表示,生成新的视频内容。注意力机制:用注意力机制来提高模型对视频内容特定部分的关注,提高生成的准确性和相关性。多模态学习:结合文本、图像和视频数据,让模型能理解和生成跨模态的内容。VideoTuna的项目地址GitHub仓库:https://github.com/VideoVerses/VideoTunaVideoTuna的应用场景内容创作:视频博主和内容创作者快速将创意文本或图像转换成视频,提高内容生产的效率和多样性。电影和视频制作:在电影制作中,生成特效场景或预览动画,减少实际拍摄的成本和时间。广告和营销:企业创建吸引人的广告视频,通过文本描述快速生成视频广告,提高营销效率。教育和培训:教育领域生成教学视频,将复杂的理论概念以视频形式直观展示,增强学习体验。新闻和报道:新闻机构快速生成新闻报道视频,提高新闻报道的时效性和吸引力。