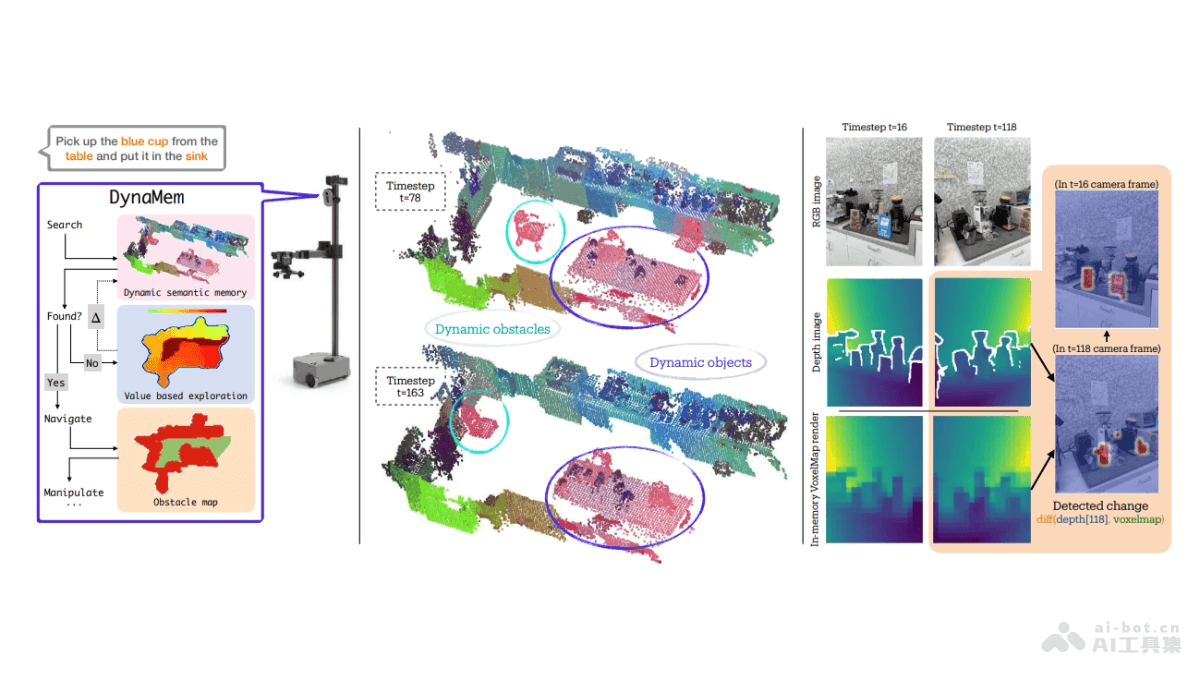
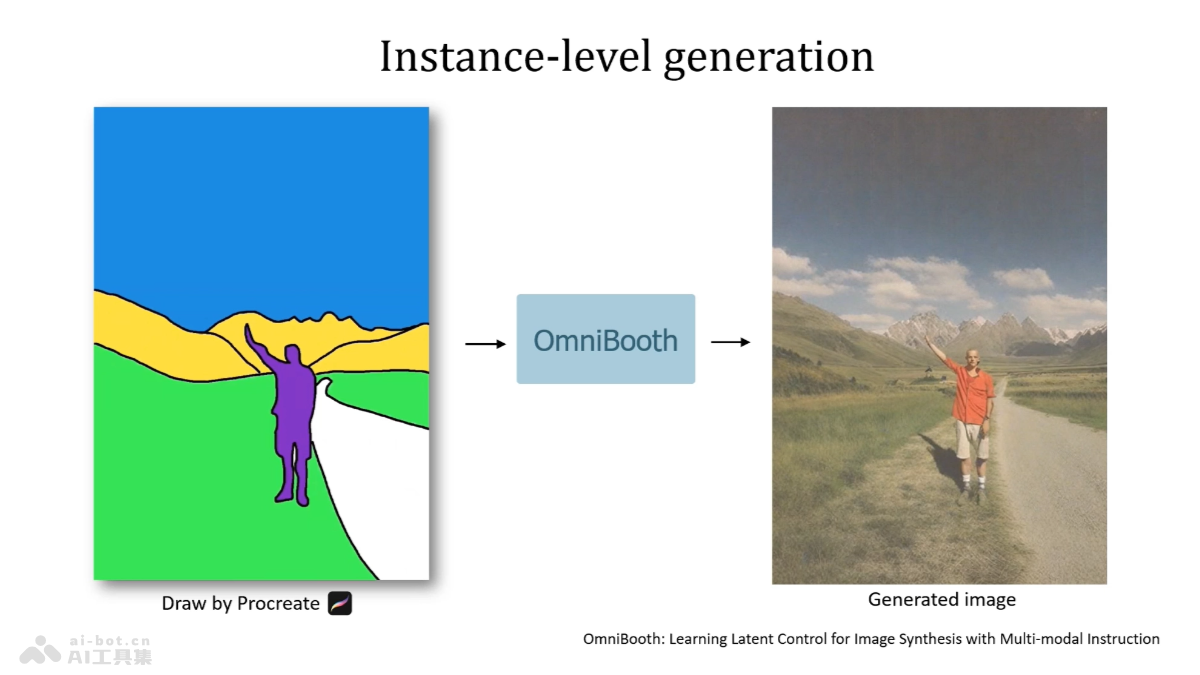
StoryDiffusion是一个先进的AI图像和视频生成框架,用于从文本描述生成具有一致性的图像和视频序列。基于Consistent Self-Attention机制增强图像间的一致性,生成的内容在身份和服饰等细节上保持连贯。StoryDiffusion引入Semantic Motion Predictor模块,在语义空间中预测图像间的运动转换,生成平滑且连贯的视频。StoryDiffusion将文本故事转化为视觉内容,包括漫画和视频形式,提高用户用文本提示控制生成内容的能力。StoryDiffusion推动视觉故事生成领域的研究,为内容创作提供新的可能性。
 StoryDiffusion的主要功能一致性图像生成:文本描述生成内容一致的图像,用于叙事和故事讲述。长视频生成:将图像转换成具有平滑过渡和一致主体的视频。文本驱动的内容控制:支持用户基于文本提示控制生成的图像和视频内容。无需训练的模块集成:Consistent Self-Attention模块无需训练直接集成到现有的图像生成模型中。滑动窗口支持长故事:滑动窗口机制支持长文本故事的图像生成,不受输入长度限制。StoryDiffusion的技术原理一致性自我注意力(Consistent Self-Attention):在自注意力计算中引入跨图像的token,增强不同图像间的一致性。语义运动预测器(Semantic Motion Predictor):基于预训练的图像编码器将图像映射到语义空间,预测中间帧的运动条件。Transformer结构预测:在语义空间中用Transformer结构预测一系列中间帧。视频扩散模型:将预测得到的语义空间向量作为控制信号,基于视频扩散模型解码成最终的视频帧。无需训练的即插即用:Consistent Self-Attention模块重用现有的自注意力权重,无需额外训练。StoryDiffusion的项目地址项目官网:storydiffusion.github.ioGitHub仓库:https://github.com/HVision-NKU/StoryDiffusionarXiv技术论文:https://arxiv.org/pdf/2405.01434StoryDiffusion的应用场景动漫和漫画创作:艺术家和作家将文本故事转化为视觉漫画或动漫,加速创作过程。教育和故事讲述:在教育领域,生成故事书或教材中的插图,帮助学生更好地理解故事内容。社交媒体内容制作:内容创作者生成吸引人的图像和视频,用于社交媒体平台,增加用户互动。广告和营销:营销人员快速生成吸引人的广告视觉内容,提高广告的吸引力。电影和游戏制作:在电影预览、游戏设计等领域,生成概念艺术或故事板。虚拟主播和视频会议:生成虚拟形象和动态背景,用于直播、视频会议或在线教育。
StoryDiffusion的主要功能一致性图像生成:文本描述生成内容一致的图像,用于叙事和故事讲述。长视频生成:将图像转换成具有平滑过渡和一致主体的视频。文本驱动的内容控制:支持用户基于文本提示控制生成的图像和视频内容。无需训练的模块集成:Consistent Self-Attention模块无需训练直接集成到现有的图像生成模型中。滑动窗口支持长故事:滑动窗口机制支持长文本故事的图像生成,不受输入长度限制。StoryDiffusion的技术原理一致性自我注意力(Consistent Self-Attention):在自注意力计算中引入跨图像的token,增强不同图像间的一致性。语义运动预测器(Semantic Motion Predictor):基于预训练的图像编码器将图像映射到语义空间,预测中间帧的运动条件。Transformer结构预测:在语义空间中用Transformer结构预测一系列中间帧。视频扩散模型:将预测得到的语义空间向量作为控制信号,基于视频扩散模型解码成最终的视频帧。无需训练的即插即用:Consistent Self-Attention模块重用现有的自注意力权重,无需额外训练。StoryDiffusion的项目地址项目官网:storydiffusion.github.ioGitHub仓库:https://github.com/HVision-NKU/StoryDiffusionarXiv技术论文:https://arxiv.org/pdf/2405.01434StoryDiffusion的应用场景动漫和漫画创作:艺术家和作家将文本故事转化为视觉漫画或动漫,加速创作过程。教育和故事讲述:在教育领域,生成故事书或教材中的插图,帮助学生更好地理解故事内容。社交媒体内容制作:内容创作者生成吸引人的图像和视频,用于社交媒体平台,增加用户互动。广告和营销:营销人员快速生成吸引人的广告视觉内容,提高广告的吸引力。电影和游戏制作:在电影预览、游戏设计等领域,生成概念艺术或故事板。虚拟主播和视频会议:生成虚拟形象和动态背景,用于直播、视频会议或在线教育。