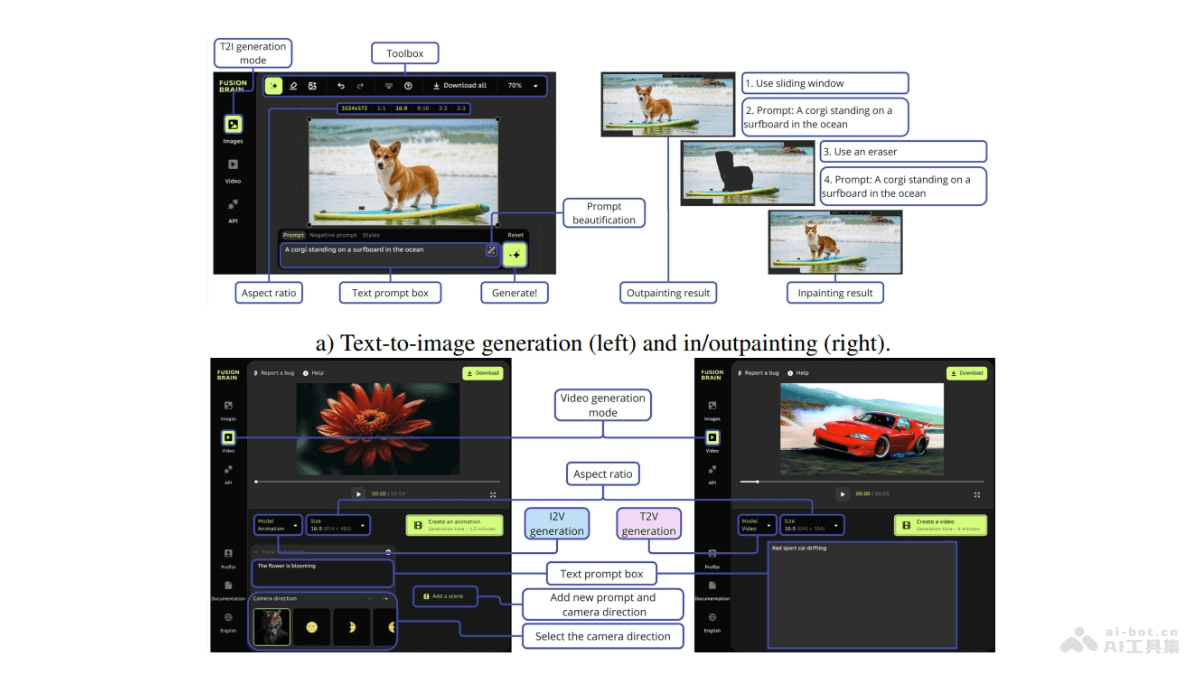
Pixtral 12B 是法国AI初创公司Mistral推出的首款多模态AI模型,能同时处理图像和文本。模型拥有 120 亿参数,模型大小约为 24GB,基于文本模型 Nemo 12B构建,能回答任意数量、任意尺寸图像的问题。Pixtral 12B 能执行为图像添加描述、统计照片中物体数量等任务。用户可以下载、微调 Pixtral 12B 模型,依据 Apache 2.0 许可证使用。Pixtral 12B 将很快在 Mistral 的聊天机器人和 API 服务平台 Le Chat 及 Le Plateforme 上开放测试。
 Pixtral 12B的主要功能图像和文本处理:Pixtral 12B 能同时处理图像和文本数据,能理解和回应与图像内容相关的问题。多模态交互:模型支持通过自然语言处理图像,用户可以上传图片或提供图片链接,对图像内容提出问题。高参数量:拥有 120 亿参数,模型在处理复杂任务时具有更高的能力和灵活性。轻量级设计:尽管参数众多,但模型的大小约为 24GB,相对较小的体积部署更加便捷,降低了能耗和硬件要求。专用视觉编码器:模型配备了专用视觉编码器,支持处理高达 1024×1024 分辨率的图像,适用高级图像处理任务。开源和可定制:Pixtral 12B 根据 Apache 2.0 许可证开源,用户可以自由下载、微调和部署模型,适应特定的应用场景。高性能:在多项基准测试中表现出色,包括 MMMU、Mathvista、ChartQA、DocVQA 等,显示在多模态理解方面的强大性能。Pixtral 12B的技术原理多模态能力:Pixtral 12B 能理解和处理图像和文本数据,能回答与图像内容相关的复杂问题。参数和架构:模型拥有120亿参数,模型大小约为24GB,这些参数为模型提供了强大的解题能力。基于40层的网络结构,具有14,336个隐藏维度和32个注意力头。视觉编码器:Pixtral 12B 配备了专门的视觉编码器,可以处理高达 1024×1024 分辨率的图像。优化推理:模型使用 TensorRT-LLM 引擎进行优化,提高推理性能。包括动态批处理、KV 缓存和量化支持,在 NVIDIA GPU 上的后训练量化。Pixtral 12B的项目地址项目官网:maginative.com/article/mistral-ai-unveils-pixtral-12bHuggingFace模型库:https://huggingface.co/mistral-community/pixtral-12b-240910Pixtral 12B的应用场景图像和文本理解:适用于需要同时解析视觉和语言信息的场景,如图像标注和内容分析。图像描述生成:模型可以为图像生成描述性文字,适用于社交媒体图片描述、图像搜索结果优化等。视觉问答:用户可以提问获取图像内容的信息,模型能理解问题并提供准确的答案,适用于智能助手和教育工具。内容创作:Pixtral 12B 可以辅助内容创作者,通过图像和文本的结合提供创意灵感,或者自动生成文章配图。智能客服:在客户服务领域,模型可以帮助理解用户上传的图像问题,提供相应的文本回答。医疗影像分析:在医疗领域,模型可以辅助分析医学影像,提供诊断支持。
Pixtral 12B的主要功能图像和文本处理:Pixtral 12B 能同时处理图像和文本数据,能理解和回应与图像内容相关的问题。多模态交互:模型支持通过自然语言处理图像,用户可以上传图片或提供图片链接,对图像内容提出问题。高参数量:拥有 120 亿参数,模型在处理复杂任务时具有更高的能力和灵活性。轻量级设计:尽管参数众多,但模型的大小约为 24GB,相对较小的体积部署更加便捷,降低了能耗和硬件要求。专用视觉编码器:模型配备了专用视觉编码器,支持处理高达 1024×1024 分辨率的图像,适用高级图像处理任务。开源和可定制:Pixtral 12B 根据 Apache 2.0 许可证开源,用户可以自由下载、微调和部署模型,适应特定的应用场景。高性能:在多项基准测试中表现出色,包括 MMMU、Mathvista、ChartQA、DocVQA 等,显示在多模态理解方面的强大性能。Pixtral 12B的技术原理多模态能力:Pixtral 12B 能理解和处理图像和文本数据,能回答与图像内容相关的复杂问题。参数和架构:模型拥有120亿参数,模型大小约为24GB,这些参数为模型提供了强大的解题能力。基于40层的网络结构,具有14,336个隐藏维度和32个注意力头。视觉编码器:Pixtral 12B 配备了专门的视觉编码器,可以处理高达 1024×1024 分辨率的图像。优化推理:模型使用 TensorRT-LLM 引擎进行优化,提高推理性能。包括动态批处理、KV 缓存和量化支持,在 NVIDIA GPU 上的后训练量化。Pixtral 12B的项目地址项目官网:maginative.com/article/mistral-ai-unveils-pixtral-12bHuggingFace模型库:https://huggingface.co/mistral-community/pixtral-12b-240910Pixtral 12B的应用场景图像和文本理解:适用于需要同时解析视觉和语言信息的场景,如图像标注和内容分析。图像描述生成:模型可以为图像生成描述性文字,适用于社交媒体图片描述、图像搜索结果优化等。视觉问答:用户可以提问获取图像内容的信息,模型能理解问题并提供准确的答案,适用于智能助手和教育工具。内容创作:Pixtral 12B 可以辅助内容创作者,通过图像和文本的结合提供创意灵感,或者自动生成文章配图。智能客服:在客户服务领域,模型可以帮助理解用户上传的图像问题,提供相应的文本回答。医疗影像分析:在医疗领域,模型可以辅助分析医学影像,提供诊断支持。