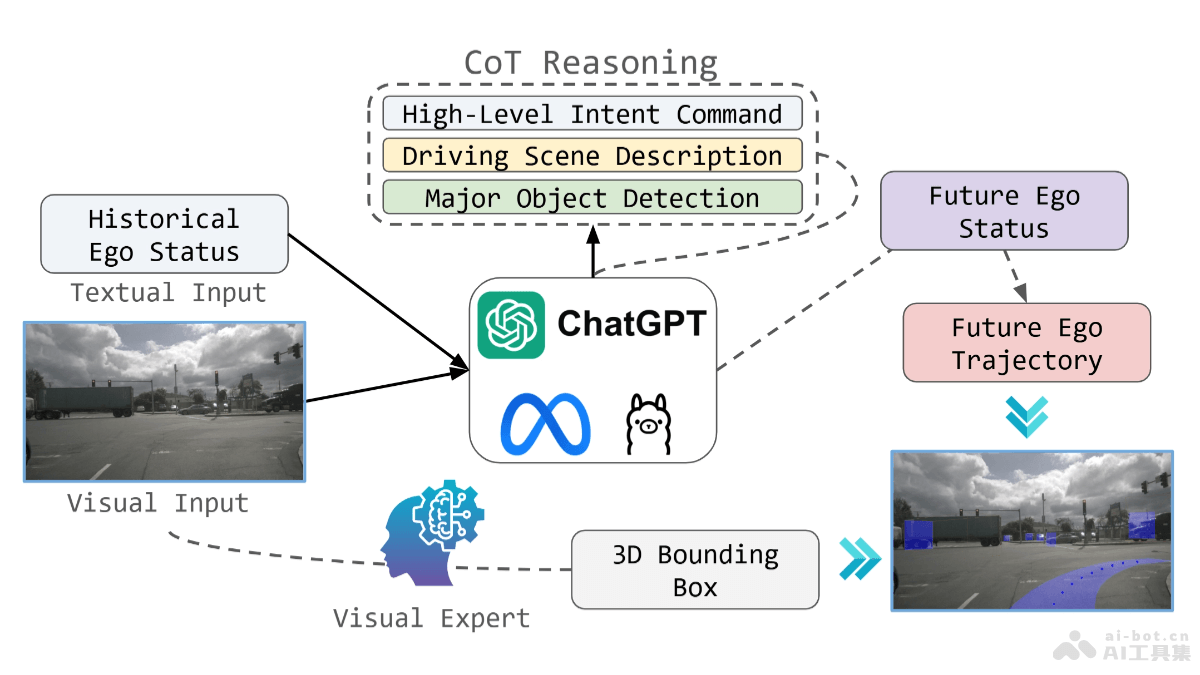
LlamaCoder 是一个开源的 AI 工具,使用 Llama 3.1 405B 模型快速生成全栈应用程序。旨在提供一种替代 Claude Artifacts 的解决方案。集成了 Sandpack、Next.js、Tailwind 和 Helicone 等组件,支持代码沙盒、应用路由、样式设计和可观测性分析。LlamaCoder 支持用户基于请求生成组件,适用构建计算器、测验应用、游戏和电商产品目录等多种应用。LlamaCoder支持数据分析和 PDF 分析,提供本地安装和使用指南,是开发者高效开发应用的有力工具。
 LlamaCoder主要功能代码生成:基于 AI 技术,根据用户的自然语言提示生成代码。应用创建:根据用户的需求快速创建全栈应用程序。组件集成:集成 Sandpack 用于代码沙盒、Next.js 用于应用路由、Tailwind 用于样式设计,以及 Helicone 用于可观测性和分析。数据驱动:支持数据分析和处理,帮助开发者更好地理解和优化应用程序。模型支持:基于 Llama 3.1 405B 模型,提供强大的语言理解和生成能力。LlamaCoder的技术原理基于 Transformer 架构:LlamaCoder 采用 Transformer 架构,一种深度学习模型,广泛应用于自然语言处理任务。Transformer 通过自注意力机制(Self-Attention)处理序列数据,能够捕捉文本中的长距离依赖关系。多层 Transformer 块:模型包含多个 Transformer 块,每个块进一步处理和提炼文本信息,增强模型对文本的理解能力。多头注意力机制:模型在不同的表示子空间中并行处理信息,更全面地理解文本内容。前馈神经网络:Transformer 块中包含前馈神经网络,用于对注意力机制的输出进行非线性变换,增加模型的表达能力。BPE 分词算法:使用 Byte Pair Encoding (BPE) 算法进行文本分词,一种高效的词汇编码方法,能处理未知词汇并减少词汇表的大小。LlamaCoder的项目地址项目官网:llamacoder.together.aiGitHub仓库:https://github.com/Nutlope/llamacoderLlamaCoder的应用场景快速原型设计:开发者用 LlamaCoder 快速生成应用程序原型,有助于在早期阶段测试和验证想法。教育和学习:学生和开发者通过 LlamaCoder 学习如何构建应用程序,无需深入了解编码的复杂性。自动化编码任务:LlamaCoder 用于自动化一些编码任务,减少开发者的工作量,专注于更复杂的开发问题。多语言支持: LlamaCoder 支持多种编程语言,帮助开发者在不同语言之间进行项目开发。本地部署:LlamaCoder 支持本地部署,开发者在自己的硬件上运行它,而不是依赖云端服务。
LlamaCoder主要功能代码生成:基于 AI 技术,根据用户的自然语言提示生成代码。应用创建:根据用户的需求快速创建全栈应用程序。组件集成:集成 Sandpack 用于代码沙盒、Next.js 用于应用路由、Tailwind 用于样式设计,以及 Helicone 用于可观测性和分析。数据驱动:支持数据分析和处理,帮助开发者更好地理解和优化应用程序。模型支持:基于 Llama 3.1 405B 模型,提供强大的语言理解和生成能力。LlamaCoder的技术原理基于 Transformer 架构:LlamaCoder 采用 Transformer 架构,一种深度学习模型,广泛应用于自然语言处理任务。Transformer 通过自注意力机制(Self-Attention)处理序列数据,能够捕捉文本中的长距离依赖关系。多层 Transformer 块:模型包含多个 Transformer 块,每个块进一步处理和提炼文本信息,增强模型对文本的理解能力。多头注意力机制:模型在不同的表示子空间中并行处理信息,更全面地理解文本内容。前馈神经网络:Transformer 块中包含前馈神经网络,用于对注意力机制的输出进行非线性变换,增加模型的表达能力。BPE 分词算法:使用 Byte Pair Encoding (BPE) 算法进行文本分词,一种高效的词汇编码方法,能处理未知词汇并减少词汇表的大小。LlamaCoder的项目地址项目官网:llamacoder.together.aiGitHub仓库:https://github.com/Nutlope/llamacoderLlamaCoder的应用场景快速原型设计:开发者用 LlamaCoder 快速生成应用程序原型,有助于在早期阶段测试和验证想法。教育和学习:学生和开发者通过 LlamaCoder 学习如何构建应用程序,无需深入了解编码的复杂性。自动化编码任务:LlamaCoder 用于自动化一些编码任务,减少开发者的工作量,专注于更复杂的开发问题。多语言支持: LlamaCoder 支持多种编程语言,帮助开发者在不同语言之间进行项目开发。本地部署:LlamaCoder 支持本地部署,开发者在自己的硬件上运行它,而不是依赖云端服务。