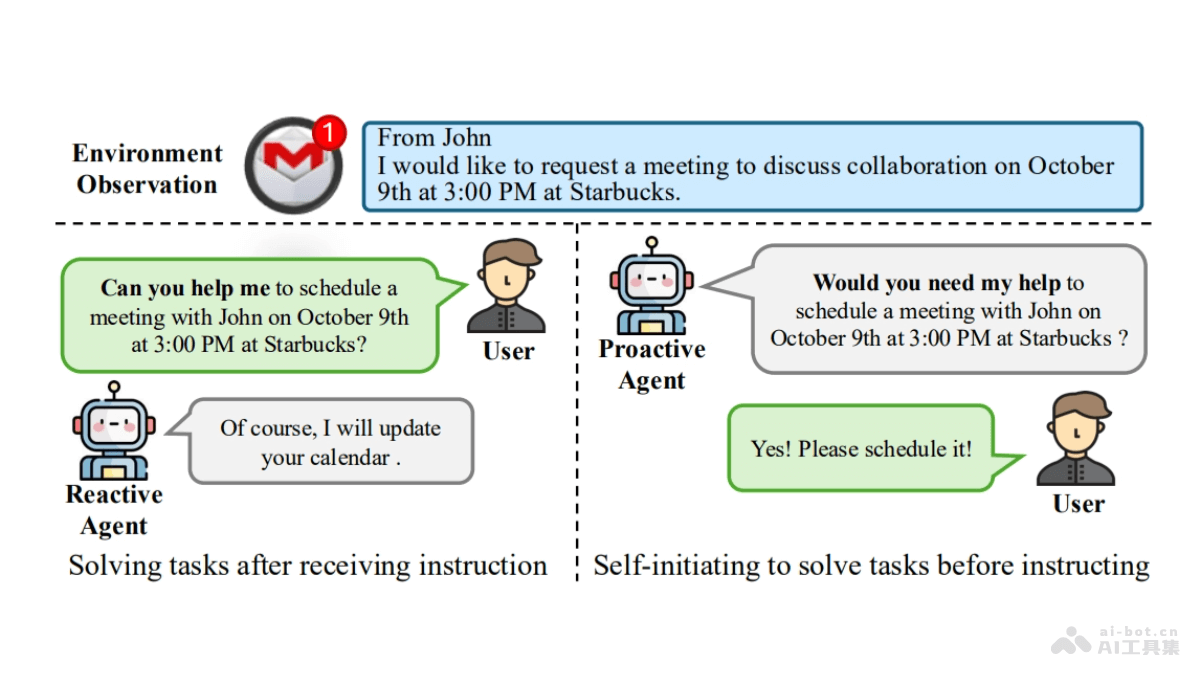
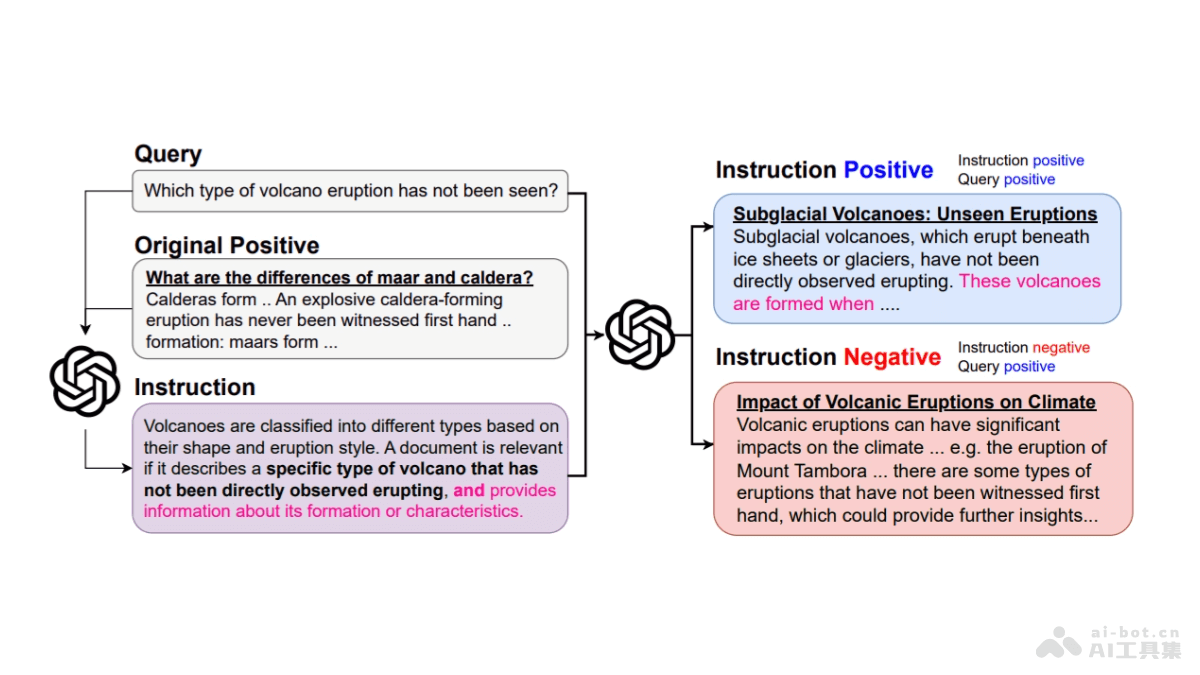
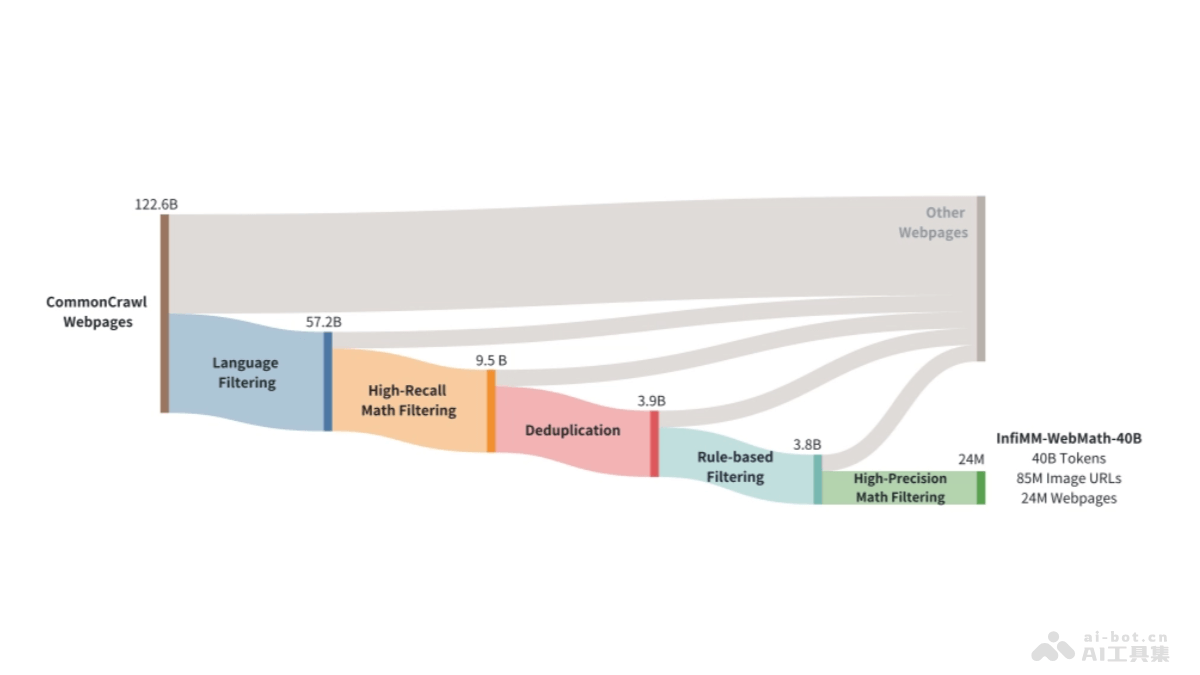
LongLLaVA是的多模态大型语言模型(MLLM),是香港中文大学(深圳)的研究人员推出。基于混合架构,结合Mamba和Transformer模块,提高处理大量图像数据的效率。LongLLaVA能在单个A100 80GB GPU上处理多达1000张图像,同时保持高性能和低内存消耗。模型基于2D池化技术压缩图像token,显著降低计算成本,保留关键的空间关系信息。LongLLaVA在视频理解、高分辨率图像分析和多模态代理等应用场景中展现出卓越的性能,特别是在检索、计数和排序任务中。
 LongLLaVA的主要功能多模态长上下文理解:处理包含大量图像的长上下文信息,适于视频理解、高分辨率图像分析等场景。高效图像处理:在单个GPU上处理多达1000张图像,展示在处理大规模视觉数据时的高效能力。混合架构优化:结合Mamba和Transformer架构,平衡模型的效率和效果。数据构建与训练策略:基于特殊的数据构建方法和分阶段训练策略,增强模型对多图像场景的理解能力。优异的基准测试表现:在多个基准测试中,展现卓越的性能,尤其在检索、计数和排序任务中。LongLLaVA的技术原理混合架构:基于混合架构,整合Mamba和Transformer模块。Mamba模块提供线性时间复杂度的序列建模能力,Transformer模块处理需要上下文学习的复杂任务。2D池化压缩:用2D池化方法压缩图像token,减少token的数量,同时保留图像间的空间关系。数据构建:在数据构建时考虑图像之间的时间和空间依赖性,设计独特的数据格式,让模型更好地理解多图像场景。渐进式训练策略:模型采用三阶段的训练方法,包括单图像对齐、单图像指令调优和多图像指令调优,逐步提升模型处理多模态长上下文的能力。效率与性能平衡:在保持高性能的同时,基于架构和训练策略的优化,实现低内存消耗和高吞吐量,展现在资源管理上的优势。多模态输入处理:能处理多种多模态输入,包括图像、视频和文本,有效地在内部混合架构中统一管理预处理输入。LongLLaVA的项目地址GitHub仓库:https://github.com/FreedomIntelligence/LongLLaVAarXiv技术论文:https://arxiv.org/pdf/2409.02889LongLLaVA的应用场景视频理解:能处理长视频序列,适用于视频内容分析、事件检测、视频摘要和视频检索等任务。高分辨率图像分析:在需要处理高分辨率图像的场景中,如卫星图像分析、医学影像诊断和病理切片分析,分解图像为子图像并理解空间依赖性。多模态助理:作为多模态助理,L提供基于图像和文本的实时信息检索和个性化服务。远程监测:在遥感领域,处理大量的遥感图像,用在环境监测、城市规划和农业分析。医疗诊断:辅助医生进行病理图像的分析,提高诊断的准确性和效率。
LongLLaVA的主要功能多模态长上下文理解:处理包含大量图像的长上下文信息,适于视频理解、高分辨率图像分析等场景。高效图像处理:在单个GPU上处理多达1000张图像,展示在处理大规模视觉数据时的高效能力。混合架构优化:结合Mamba和Transformer架构,平衡模型的效率和效果。数据构建与训练策略:基于特殊的数据构建方法和分阶段训练策略,增强模型对多图像场景的理解能力。优异的基准测试表现:在多个基准测试中,展现卓越的性能,尤其在检索、计数和排序任务中。LongLLaVA的技术原理混合架构:基于混合架构,整合Mamba和Transformer模块。Mamba模块提供线性时间复杂度的序列建模能力,Transformer模块处理需要上下文学习的复杂任务。2D池化压缩:用2D池化方法压缩图像token,减少token的数量,同时保留图像间的空间关系。数据构建:在数据构建时考虑图像之间的时间和空间依赖性,设计独特的数据格式,让模型更好地理解多图像场景。渐进式训练策略:模型采用三阶段的训练方法,包括单图像对齐、单图像指令调优和多图像指令调优,逐步提升模型处理多模态长上下文的能力。效率与性能平衡:在保持高性能的同时,基于架构和训练策略的优化,实现低内存消耗和高吞吐量,展现在资源管理上的优势。多模态输入处理:能处理多种多模态输入,包括图像、视频和文本,有效地在内部混合架构中统一管理预处理输入。LongLLaVA的项目地址GitHub仓库:https://github.com/FreedomIntelligence/LongLLaVAarXiv技术论文:https://arxiv.org/pdf/2409.02889LongLLaVA的应用场景视频理解:能处理长视频序列,适用于视频内容分析、事件检测、视频摘要和视频检索等任务。高分辨率图像分析:在需要处理高分辨率图像的场景中,如卫星图像分析、医学影像诊断和病理切片分析,分解图像为子图像并理解空间依赖性。多模态助理:作为多模态助理,L提供基于图像和文本的实时信息检索和个性化服务。远程监测:在遥感领域,处理大量的遥感图像,用在环境监测、城市规划和农业分析。医疗诊断:辅助医生进行病理图像的分析,提高诊断的准确性和效率。