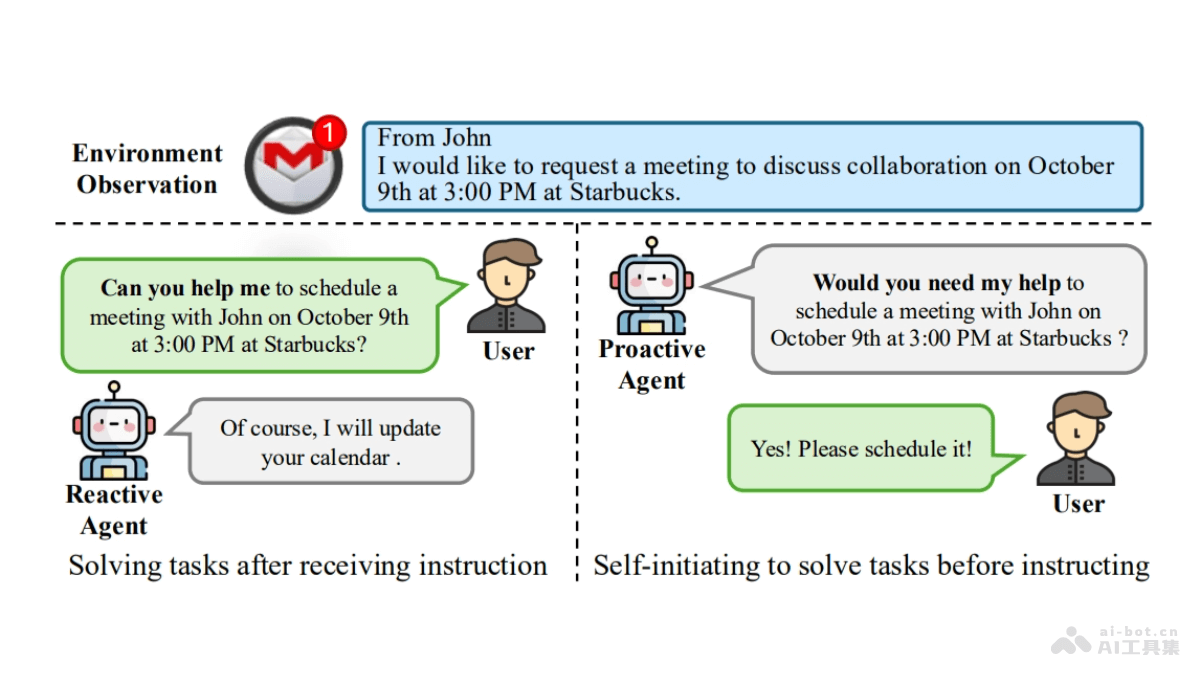
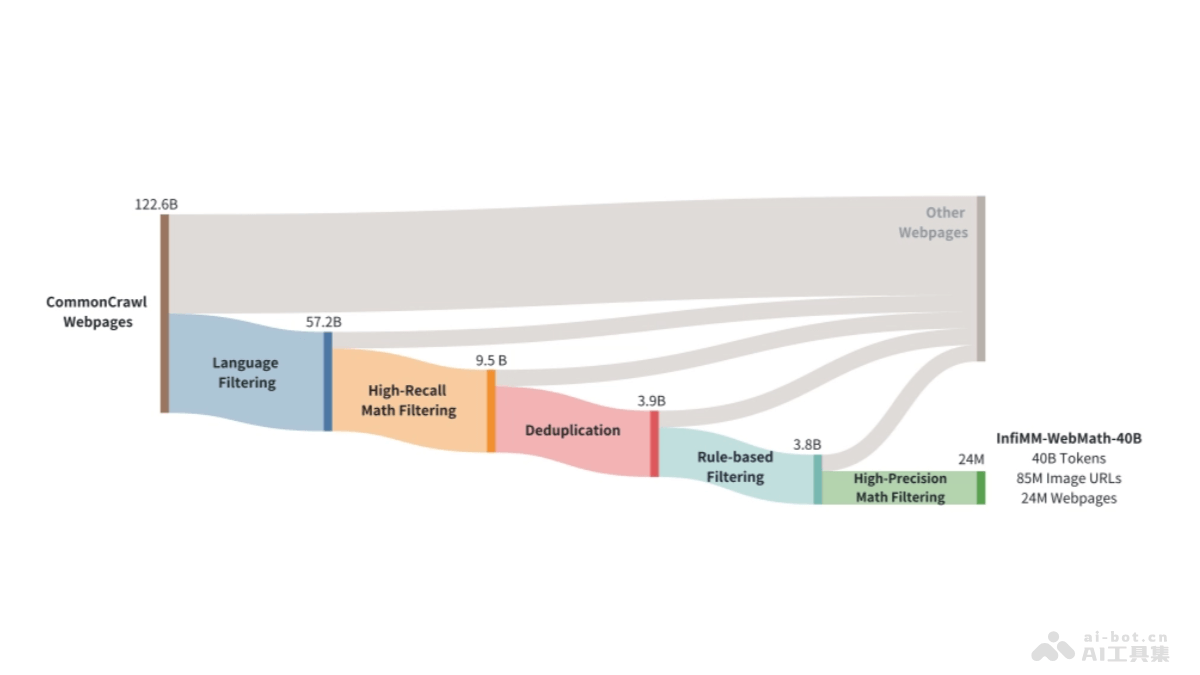
NVLM是NVIDIA推出的前沿多模态大型语言模型(LLMs),在视觉-语言任务上达到与顶尖专有模型(如GPT-4o)和开放访问模型(如Llama 3-V 405B和InternVL 2)相匹敌的性能。NVLM 1.0家族包括三种架构:仅解码器模型NVLM-D、基于交叉注意力的模型NVLM-X和混合架构NVLM-H。三种架构在多模态训练后,保持了文本性能,在某些情况下超过了它们的LLM主干。NVLM基于精心策划的多模态预训练和监督微调数据集,展现了卓越的性能,尤其在数学和编码任务上。
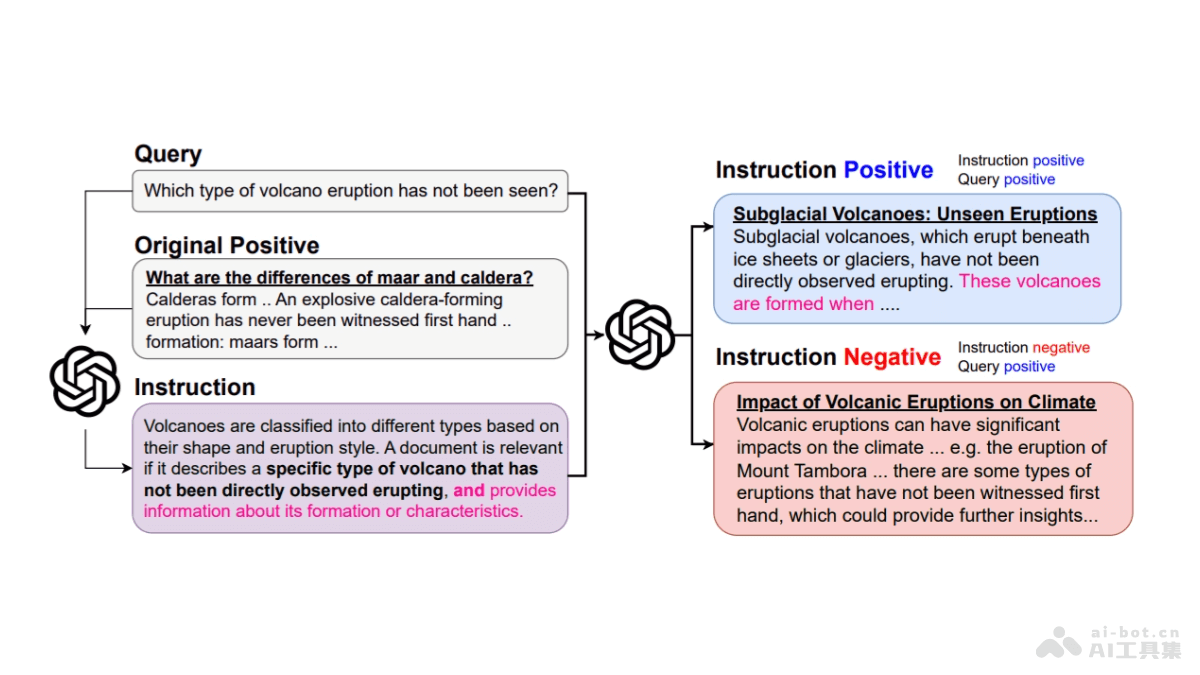
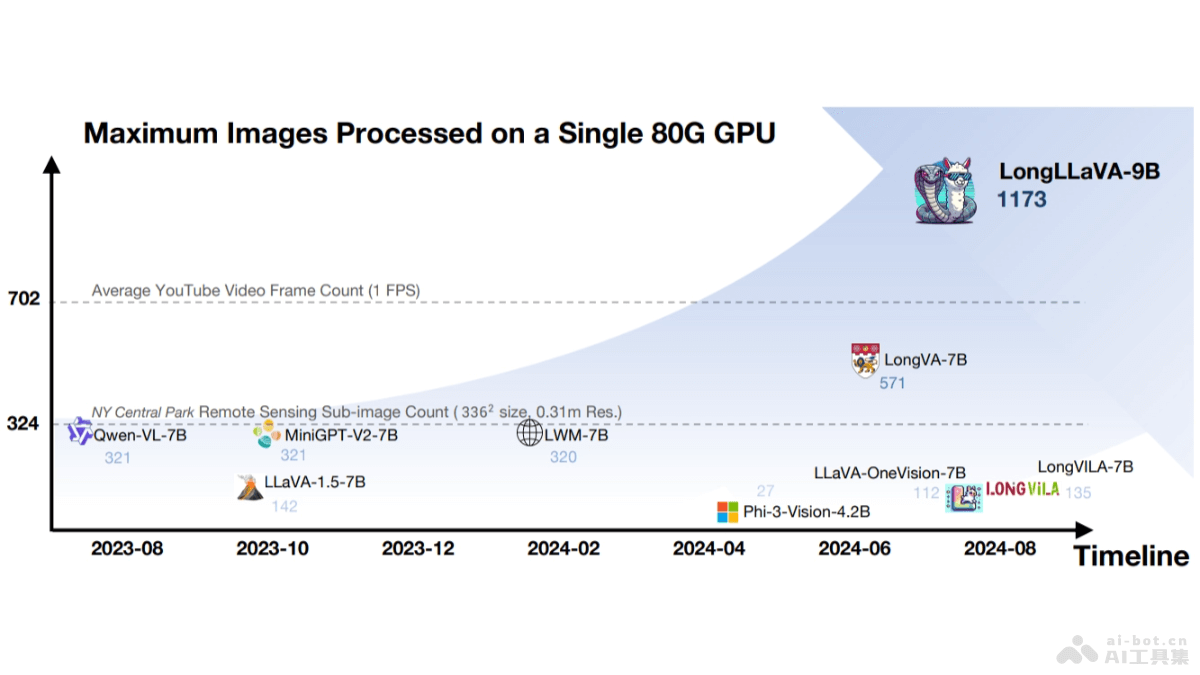
 NVLM的主要功能图像理解:能识别和理解图像内容,包括物体、场景和活动。语言理解:理解自然语言文本,包括词汇、句子和语义。跨模态融合:将视觉信息和语言信息结合起来,实现更深层次的理解。图像描述生成:为图像生成描述性文本。视觉推理:进行复杂的视觉推理,如预测、比较和分析。多模态翻译:在不同模态之间进行信息转换,如将文本描述转换为视觉表示。NVLM的技术原理模型架构:NVLM-D(仅解码器模型):将图像特征直接嵌入到LLM的解码器中,统一处理所有模态。NVLM-X(交叉注意力模型):使用交叉注意力机制处理图像特征,保持LLM主干的参数冻结,以维持文本性能。NVLM-H(混合模型):结合了NVLM-D和NVLM-X的优点,同时处理全局缩略图和局部图像特征。动态高分辨率输入:将高分辨率图像分割成多个平铺(tiles),每个平铺独立处理,然后合并结果,提高对图像细节的处理能力。1-D平铺标签设计:在处理高分辨率图像时,引入1-D平铺标签(tile tags),帮助模型理解图像的不同部分及其在整体中的位置。多模态预训练和监督微调:用高质量的多模态数据集进行预训练,及针对性的任务数据集进行监督微调,提升模型在特定任务上的性能。NVLM的项目地址项目官网:nvlm-project.github.ioHuggingFace模型库:https://huggingface.co/collections/nvidia/nvlm-10-66e9f407c764a0ee6e37b7f4arXiv技术论文:https://arxiv.org/pdf/2409.11402NVLM的应用场景图像和视频描述:自动生成图像或视频内容的描述,适于社交媒体、内容管理和搜索引擎优化。视觉问答(VQA):回答有关图像内容的问题,适于客户服务、教育和信息检索。文档理解和OCR:从扫描的文档、票据和表格中提取文本和信息,适于自动化办公和档案管理。多模态搜索:通过图像或文本查询检索相关信息,适于电子商务和内容推荐系统。辅助驾驶和机器人:理解和响应视觉环境中的指令,用在自动驾驶车辆和机器人导航。
NVLM的主要功能图像理解:能识别和理解图像内容,包括物体、场景和活动。语言理解:理解自然语言文本,包括词汇、句子和语义。跨模态融合:将视觉信息和语言信息结合起来,实现更深层次的理解。图像描述生成:为图像生成描述性文本。视觉推理:进行复杂的视觉推理,如预测、比较和分析。多模态翻译:在不同模态之间进行信息转换,如将文本描述转换为视觉表示。NVLM的技术原理模型架构:NVLM-D(仅解码器模型):将图像特征直接嵌入到LLM的解码器中,统一处理所有模态。NVLM-X(交叉注意力模型):使用交叉注意力机制处理图像特征,保持LLM主干的参数冻结,以维持文本性能。NVLM-H(混合模型):结合了NVLM-D和NVLM-X的优点,同时处理全局缩略图和局部图像特征。动态高分辨率输入:将高分辨率图像分割成多个平铺(tiles),每个平铺独立处理,然后合并结果,提高对图像细节的处理能力。1-D平铺标签设计:在处理高分辨率图像时,引入1-D平铺标签(tile tags),帮助模型理解图像的不同部分及其在整体中的位置。多模态预训练和监督微调:用高质量的多模态数据集进行预训练,及针对性的任务数据集进行监督微调,提升模型在特定任务上的性能。NVLM的项目地址项目官网:nvlm-project.github.ioHuggingFace模型库:https://huggingface.co/collections/nvidia/nvlm-10-66e9f407c764a0ee6e37b7f4arXiv技术论文:https://arxiv.org/pdf/2409.11402NVLM的应用场景图像和视频描述:自动生成图像或视频内容的描述,适于社交媒体、内容管理和搜索引擎优化。视觉问答(VQA):回答有关图像内容的问题,适于客户服务、教育和信息检索。文档理解和OCR:从扫描的文档、票据和表格中提取文本和信息,适于自动化办公和档案管理。多模态搜索:通过图像或文本查询检索相关信息,适于电子商务和内容推荐系统。辅助驾驶和机器人:理解和响应视觉环境中的指令,用在自动驾驶车辆和机器人导航。