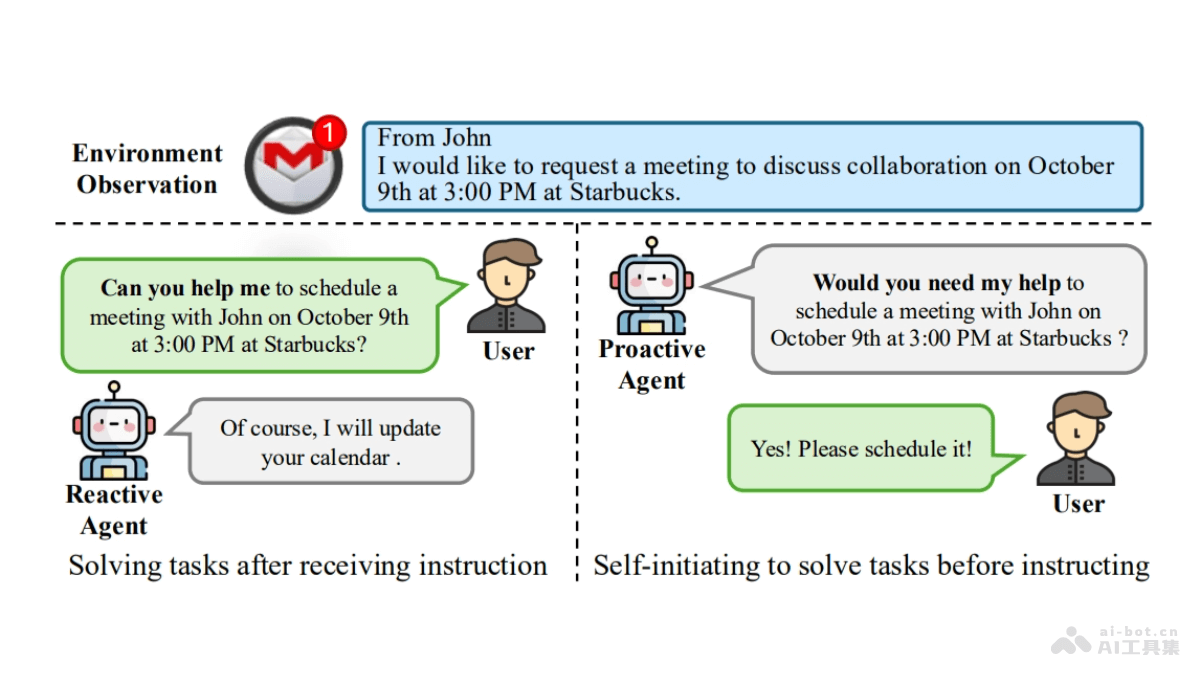
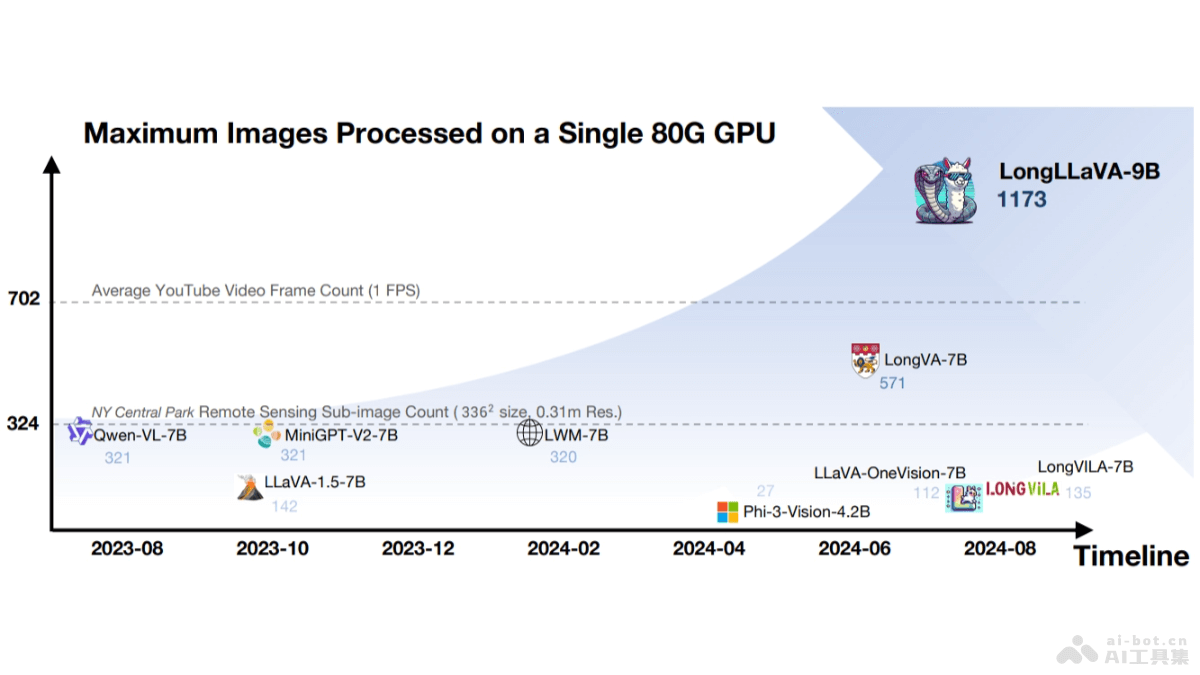
Promptriever 是约翰斯·霍普金斯大学和Samaya AI联合推出的新型检索模型,能像语言模型一样接受自然语言提示,用直观的方式响应用户的搜索需求。Promptriever 基于 MS MARCO 数据集的指令训练集进行训练,在标准检索任务上表现出色,能更有效地遵循详细指令,提高对查询的鲁棒性和检索性能。Promptriever展示了将大型语言模型的提示技术与信息检索相结合的潜力。
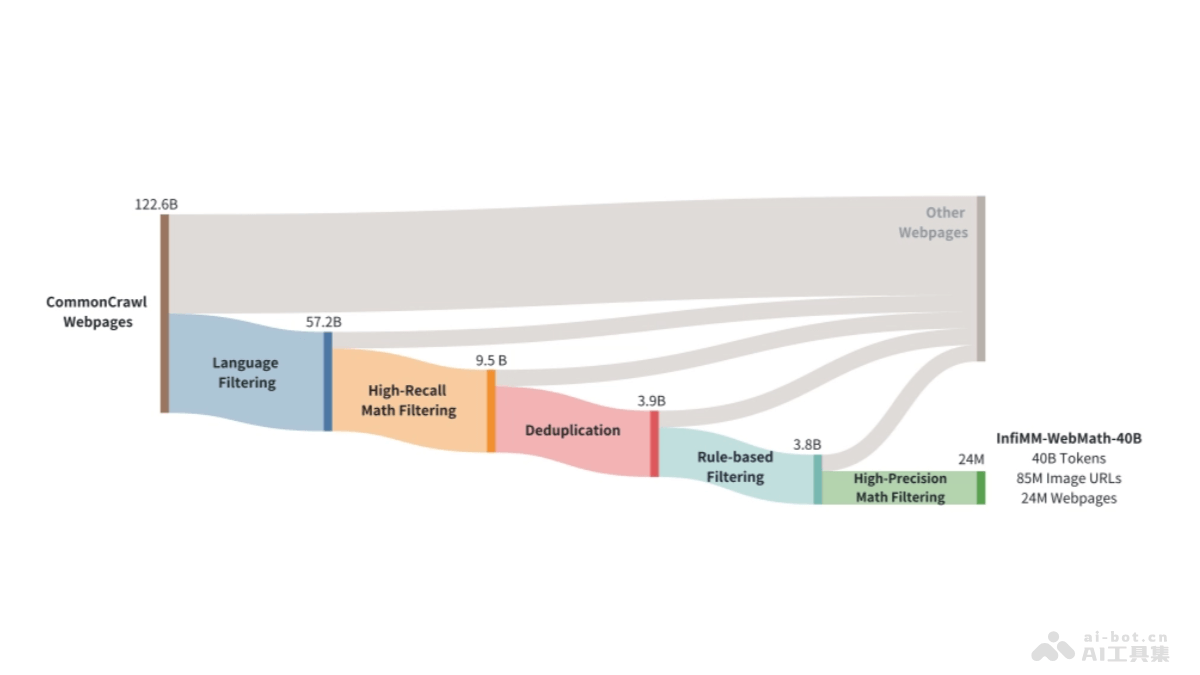
 Promptriever的主要功能接受自然语言提示:能理解并响应自然语言形式的提示,让用户用更自然的方式表达搜索需求。动态调整相关性:根据用户的具体指令动态调整搜索结果的相关性,例如,根据用户对搜索结果的具体要求(如时间范围、特定属性)过滤和排序文档。提高检索鲁棒性:基于理解和处理自然语言中的细微差别,增强模型对于不同查询表达的鲁棒性。提升检索性能:基于提示进行超参数搜索,改善检索结果的质量。Promptriever的技术原理双编码器架构:基于双编码器(bi-encoder)架构,用大型语言模型(如 LLaMA-2 7B)作为其背后的支持模型。指令训练数据集:从 MS MARCO 数据集中筛选和发布新的指令级训练集,在训练中包含定义查询相关性的自然语言指令。指令生成:用语言模型生成更具体的指令,指令能添加额外的要求或明确排除某些类型的文档。指令负例挖掘:基于生成和过滤(query, passage)对,创建出在加入特定指令后相关性降低的负例,迫使模型学习如何根据指令调整相关性判断。零样本提示技术:基于零样本提示技术进行超参数搜索,类似于语言模型的提示,改善检索性能。Promptriever的项目地址GitHub仓库:https://github.com/orionw/promptrieverarXiv技术论文:https://arxiv.org/pdf/2409.11136Promptriever的应用场景搜索引擎优化:提供更精准的搜索结果,基于理解用户的自然语言查询和指令,改善搜索体验。智能助手和聊天机器人:理解和执行用户的复杂指令,提供更个性化和上下文相关的回答。企业内部搜索:在企业知识库中快速准确地检索特定信息,提高工作效率。学术研究和文献检索:根据研究者的详细查询指令,检索特定的学术论文和文献资料。电子商务:根据用户的购物需求和偏好,提供定制化的搜索结果和产品推荐。
Promptriever的主要功能接受自然语言提示:能理解并响应自然语言形式的提示,让用户用更自然的方式表达搜索需求。动态调整相关性:根据用户的具体指令动态调整搜索结果的相关性,例如,根据用户对搜索结果的具体要求(如时间范围、特定属性)过滤和排序文档。提高检索鲁棒性:基于理解和处理自然语言中的细微差别,增强模型对于不同查询表达的鲁棒性。提升检索性能:基于提示进行超参数搜索,改善检索结果的质量。Promptriever的技术原理双编码器架构:基于双编码器(bi-encoder)架构,用大型语言模型(如 LLaMA-2 7B)作为其背后的支持模型。指令训练数据集:从 MS MARCO 数据集中筛选和发布新的指令级训练集,在训练中包含定义查询相关性的自然语言指令。指令生成:用语言模型生成更具体的指令,指令能添加额外的要求或明确排除某些类型的文档。指令负例挖掘:基于生成和过滤(query, passage)对,创建出在加入特定指令后相关性降低的负例,迫使模型学习如何根据指令调整相关性判断。零样本提示技术:基于零样本提示技术进行超参数搜索,类似于语言模型的提示,改善检索性能。Promptriever的项目地址GitHub仓库:https://github.com/orionw/promptrieverarXiv技术论文:https://arxiv.org/pdf/2409.11136Promptriever的应用场景搜索引擎优化:提供更精准的搜索结果,基于理解用户的自然语言查询和指令,改善搜索体验。智能助手和聊天机器人:理解和执行用户的复杂指令,提供更个性化和上下文相关的回答。企业内部搜索:在企业知识库中快速准确地检索特定信息,提高工作效率。学术研究和文献检索:根据研究者的详细查询指令,检索特定的学术论文和文献资料。电子商务:根据用户的购物需求和偏好,提供定制化的搜索结果和产品推荐。