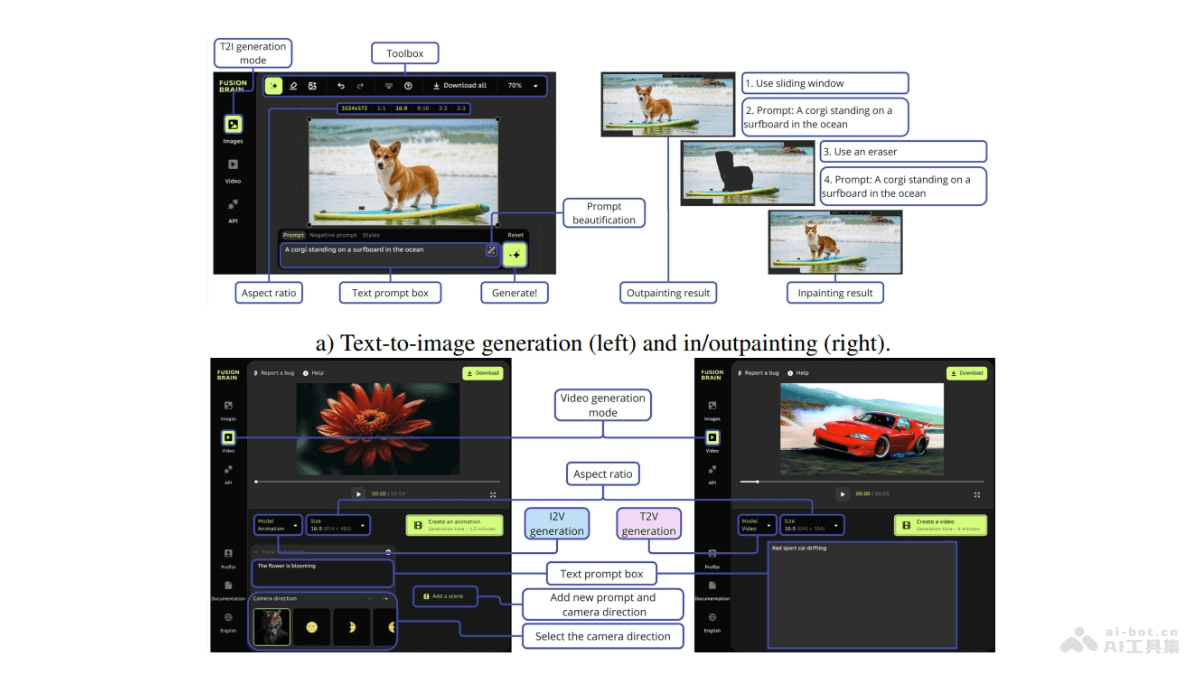
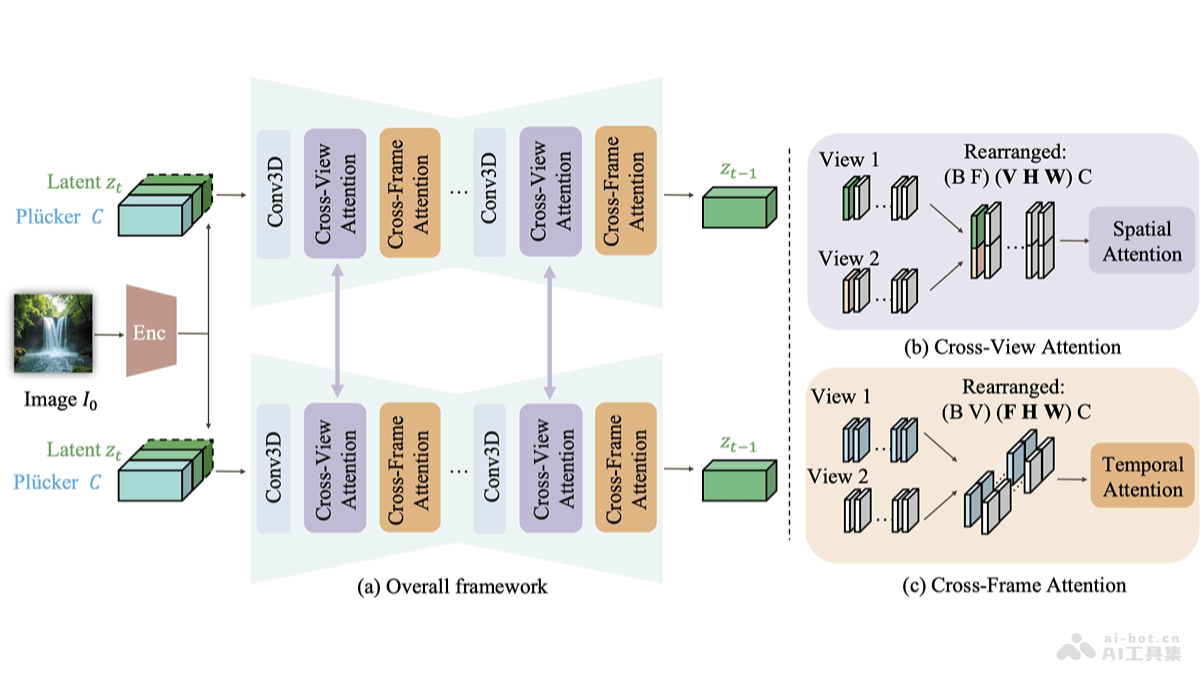
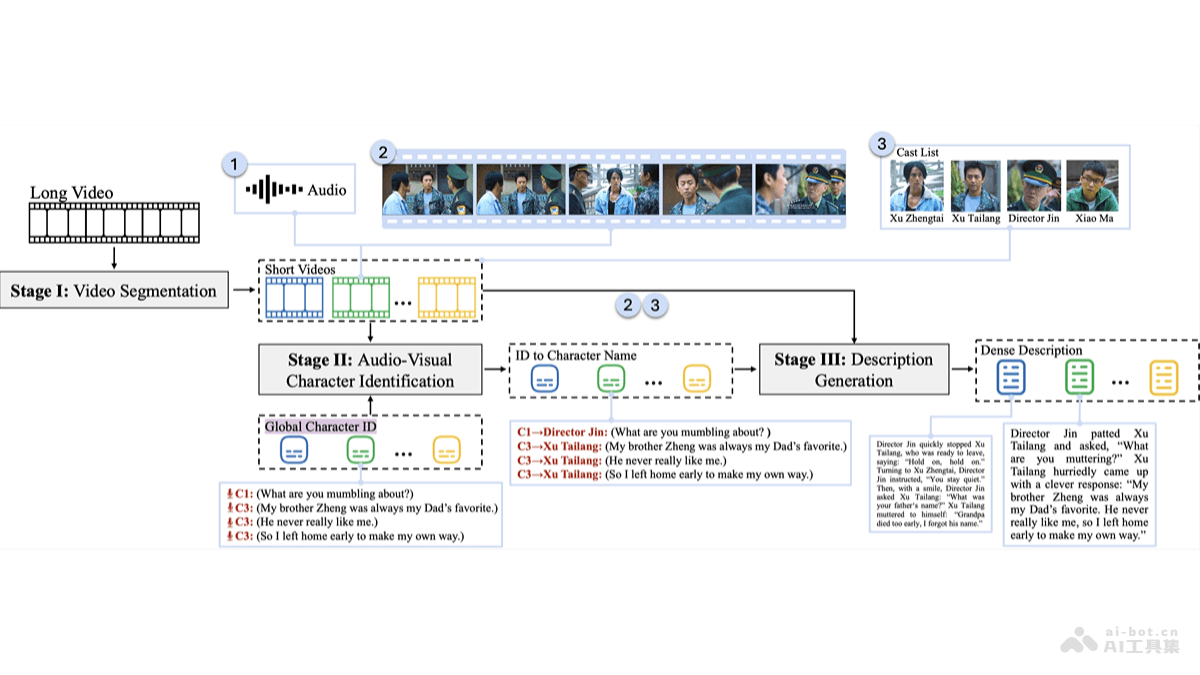
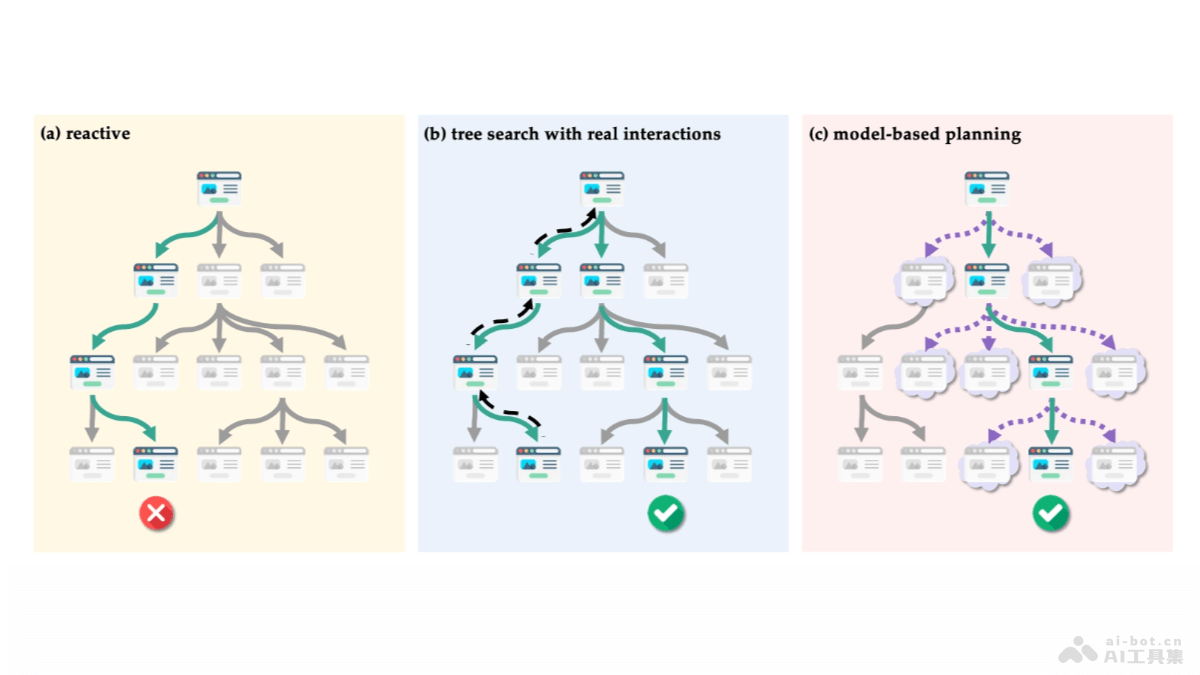
XVERSE-MoE-A36B是由元象推出的中国最大的MoE(Mixture of Experts,混合专家模型)开源大模型。模型具有2550亿的总参数和360亿的激活参数,性能上与超过100B参数的大模型相媲美,实现跨级的性能跃升。相比于传统的稠密模型,XVERSE-MoE-A36B在训练时间上减少30%,推理性能提升100%,大幅降低每token的成本,使AI应用实现低成本部署。
 XVERSE-MoE-A36B的主要功能大规模参数:模型总参数达到 2550 亿(255B),激活参数为 360 亿(36B),提供与百亿级参数大模型相媲美的性能。高效性能:相比传统的密集模型,XVERSE-MoE-A36B 在训练时间上减少 30%,推理性能提升了100%,显著降低了每 token 的成本。开源免费商用:模型全面开源,并且无条件免费商用,为中小企业、研究者和开发者提供广泛的应用可能性。MoE 架构优势:采用业界前沿的 MoE 架构,组合多个细分领域的专家模型,实现在扩大模型规模的同时,控制训练和推理的计算成本。技术创新:在 MoE 架构上进行多项技术创新,包括 4D 拓扑设计、专家路由与预丢弃策略、数据动态切换等,提高模型的效率和效果。XVERSE-MoE-A36B的技术原理稀疏激活(Sparse Activation):在 MoE 架构中,不是所有的专家网络会对每个输入进行处理。模型根据输入的特性选择性地激活一部分专家,减少了计算资源的消耗,提高模型的运行效率。专家网络(Expert Networks):MoE 模型由多个专家网络组成,每个专家网络都是一个小型的神经网络,在特定任务上进行专业化训练。专家网络并行处理,增加模型的灵活性和扩展性。门控机制(Gating Mechanism):MoE 模型包含一个门控网络,负责决定哪些专家网络应该被激活来处理特定的输入。门控网络通过学习输入数据的特征来动态地路由信息至最合适的专家。负载均衡(Load Balancing):为避免某些专家网络过载而其他专家网络空闲的情况,MoE 模型采用负载均衡策略,确保所有专家网络都能均匀地参与到模型的推理过程中。4D 拓扑设计:为优化专家之间的通信效率,XVERSE-MoE-A36B 采用 4D 拓扑架构,可以平衡通信、显存和计算资源的分配,减少通信负担。XVERSE-MoE-A36B的项目地址项目官网:chat.xverse.cnGitHub仓库:https://github.com/xverse-ai/XVERSE-MoE-A36BHuggingFace模型库:https://huggingface.co/xverse/XVERSE-MoE-A36BXVERSE-MoE-A36B的应用场景自然语言处理(NLP):用于文本生成、机器翻译、情感分析、文本摘要、问答系统等。内容创作与娱乐:辅助创作文章、故事、诗歌,或者在游戏和互动媒体中生成逼真的对话和情节。智能客服:提供自动化的客户服务,通过聊天机器人解答用户问题,提供个性化服务。教育和学习辅助:个性化教育内容的生成,语言学习辅助,或者作为编程和技能学习的虚拟助手。信息检索和推荐系统:改进搜索引擎的查询响应,为用户提供更准确的信息和个性化推荐。数据挖掘和分析:分析大量文本数据,提取有用信息,支持决策制定。
XVERSE-MoE-A36B的主要功能大规模参数:模型总参数达到 2550 亿(255B),激活参数为 360 亿(36B),提供与百亿级参数大模型相媲美的性能。高效性能:相比传统的密集模型,XVERSE-MoE-A36B 在训练时间上减少 30%,推理性能提升了100%,显著降低了每 token 的成本。开源免费商用:模型全面开源,并且无条件免费商用,为中小企业、研究者和开发者提供广泛的应用可能性。MoE 架构优势:采用业界前沿的 MoE 架构,组合多个细分领域的专家模型,实现在扩大模型规模的同时,控制训练和推理的计算成本。技术创新:在 MoE 架构上进行多项技术创新,包括 4D 拓扑设计、专家路由与预丢弃策略、数据动态切换等,提高模型的效率和效果。XVERSE-MoE-A36B的技术原理稀疏激活(Sparse Activation):在 MoE 架构中,不是所有的专家网络会对每个输入进行处理。模型根据输入的特性选择性地激活一部分专家,减少了计算资源的消耗,提高模型的运行效率。专家网络(Expert Networks):MoE 模型由多个专家网络组成,每个专家网络都是一个小型的神经网络,在特定任务上进行专业化训练。专家网络并行处理,增加模型的灵活性和扩展性。门控机制(Gating Mechanism):MoE 模型包含一个门控网络,负责决定哪些专家网络应该被激活来处理特定的输入。门控网络通过学习输入数据的特征来动态地路由信息至最合适的专家。负载均衡(Load Balancing):为避免某些专家网络过载而其他专家网络空闲的情况,MoE 模型采用负载均衡策略,确保所有专家网络都能均匀地参与到模型的推理过程中。4D 拓扑设计:为优化专家之间的通信效率,XVERSE-MoE-A36B 采用 4D 拓扑架构,可以平衡通信、显存和计算资源的分配,减少通信负担。XVERSE-MoE-A36B的项目地址项目官网:chat.xverse.cnGitHub仓库:https://github.com/xverse-ai/XVERSE-MoE-A36BHuggingFace模型库:https://huggingface.co/xverse/XVERSE-MoE-A36BXVERSE-MoE-A36B的应用场景自然语言处理(NLP):用于文本生成、机器翻译、情感分析、文本摘要、问答系统等。内容创作与娱乐:辅助创作文章、故事、诗歌,或者在游戏和互动媒体中生成逼真的对话和情节。智能客服:提供自动化的客户服务,通过聊天机器人解答用户问题,提供个性化服务。教育和学习辅助:个性化教育内容的生成,语言学习辅助,或者作为编程和技能学习的虚拟助手。信息检索和推荐系统:改进搜索引擎的查询响应,为用户提供更准确的信息和个性化推荐。数据挖掘和分析:分析大量文本数据,提取有用信息,支持决策制定。