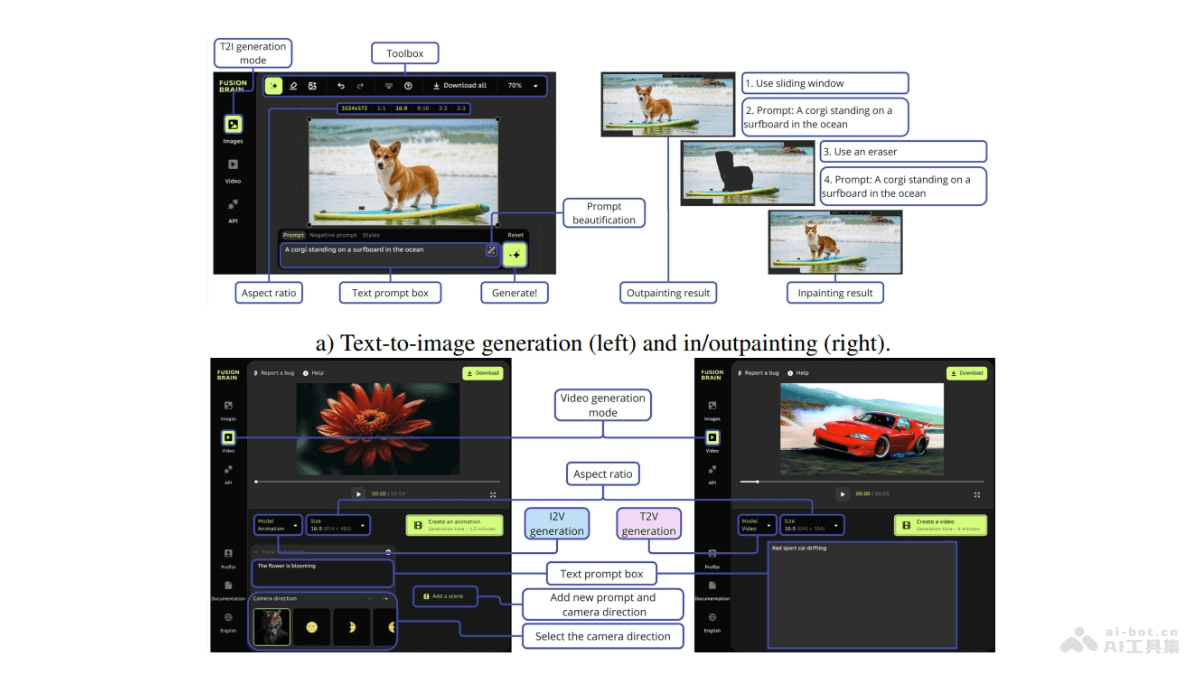
PersonaTalk是字节跳动推出的基于注意力机制的两阶段框架,用在实现高保真度和个性化的视觉配音。PersonaTalk能在合成与目标音频精准唇形同步的视频的同时,保留说话者的独特说话风格和面部细节。第一阶段涉及风格感知的音频编码和唇形同步几何生成,第二阶段用双注意力面部渲染器渲染目标几何图形的纹理。PersonaTalk在视觉质量、唇形同步精度和个性保留方面展现出比现有技术更优的性能(包括Wav2Lip、VideoReTalking、DINet和IP_LAP),作为一个通用框架,能达到与特定人方法相媲美的效果。
 PersonaTalk的主要功能唇形同步:确保视频中人物的嘴型动作与输入音频精确匹配。个性保留:在视频合成过程中,保留说话者的独特风格和面部特征。风格感知:基于分析说话者的3D面部几何信息,学习说话者说话风格,融入到音频特征中。双注意力面部渲染:用Lip-Attention和Face-Attention两个并行的注意力机制,分别处理唇部和其他面部区域的纹理渲染,生成具有丰富细节的面部图像。PersonaTalk的技术原理几何构建:风格感知音频编码:用HuBERT等预训练模型将音频信号转换为丰富的上下文语音表示,基于交叉注意力层将说话风格注入音频特征中。唇形同步几何生成:用风格化的音频特征驱动说话者的模板几何形状,基于多个交叉注意力和自注意力层生成与音频同步的唇形几何形状。面部渲染:几何与纹理编码:将参考视频的几何形状和纹理编码到潜在空间中,便于后续的处理。双注意力纹理采样:基于两个并行的交叉注意力层(Lip-Attention和Face-Attention),分别从不同的参考帧中采样唇部和面部的纹理。参考帧选择策略:为唇部和面部纹理选择不同的参考帧,增强纹理采样的多样性和全局一致性。纹理解码:将采样的纹理从潜在空间解码回像素空间,保护面部几何结构,生成最终的面部图像。PersonaTalk的项目地址项目官网:grisoon.github.io/PersonaTalkarXiv技术论文:https://arxiv.org/pdf/2409.05379PersonaTalk的应用场景电影和视频制作:在电影后期制作中,PersonaTalk为角色配音,特别是当原始录音不满意或需要更改语言时,生成与角色嘴型同步的配音视频。视频游戏:在游戏开发中,用在生成非玩家角色(NPC)的逼真对话,提供更加沉浸式的游戏体验。虚拟助手和数字人:为虚拟助手或数字人提供更加自然和逼真的语音及面部表情同步,提升用户交互体验。语言学习应用:在语言学习软件中,P生成教师或虚拟角色的唇形同步视频,帮助学习者更好地学习和模仿发音。新闻和媒体广播:用在将新闻主播的讲话翻译成不同语言,保持原有的面部表情和嘴型,提高多语言广播的自然度和准确性。
PersonaTalk的主要功能唇形同步:确保视频中人物的嘴型动作与输入音频精确匹配。个性保留:在视频合成过程中,保留说话者的独特风格和面部特征。风格感知:基于分析说话者的3D面部几何信息,学习说话者说话风格,融入到音频特征中。双注意力面部渲染:用Lip-Attention和Face-Attention两个并行的注意力机制,分别处理唇部和其他面部区域的纹理渲染,生成具有丰富细节的面部图像。PersonaTalk的技术原理几何构建:风格感知音频编码:用HuBERT等预训练模型将音频信号转换为丰富的上下文语音表示,基于交叉注意力层将说话风格注入音频特征中。唇形同步几何生成:用风格化的音频特征驱动说话者的模板几何形状,基于多个交叉注意力和自注意力层生成与音频同步的唇形几何形状。面部渲染:几何与纹理编码:将参考视频的几何形状和纹理编码到潜在空间中,便于后续的处理。双注意力纹理采样:基于两个并行的交叉注意力层(Lip-Attention和Face-Attention),分别从不同的参考帧中采样唇部和面部的纹理。参考帧选择策略:为唇部和面部纹理选择不同的参考帧,增强纹理采样的多样性和全局一致性。纹理解码:将采样的纹理从潜在空间解码回像素空间,保护面部几何结构,生成最终的面部图像。PersonaTalk的项目地址项目官网:grisoon.github.io/PersonaTalkarXiv技术论文:https://arxiv.org/pdf/2409.05379PersonaTalk的应用场景电影和视频制作:在电影后期制作中,PersonaTalk为角色配音,特别是当原始录音不满意或需要更改语言时,生成与角色嘴型同步的配音视频。视频游戏:在游戏开发中,用在生成非玩家角色(NPC)的逼真对话,提供更加沉浸式的游戏体验。虚拟助手和数字人:为虚拟助手或数字人提供更加自然和逼真的语音及面部表情同步,提升用户交互体验。语言学习应用:在语言学习软件中,P生成教师或虚拟角色的唇形同步视频,帮助学习者更好地学习和模仿发音。新闻和媒体广播:用在将新闻主播的讲话翻译成不同语言,保持原有的面部表情和嘴型,提高多语言广播的自然度和准确性。